
그래프 이론(Graph Theory)
그래프
노드(Node)와 노드 사이에 연결된 간선(Edge)의 정보를 가지고 있는 자료구조로 인접 행렬(2차원 배열 사용)과 인접 리스트(리스트 사용)를 이용해서 구현할 수 있다.
서로소 집합(Disjoint Sets)
공통 원소가 없는 두 집합이다. 예를 들어 집합 {1, 2}와 집합 {3, 4}는 서로소 관계이다. 반면에 집합 {1, 2}와 집합 {2, 3}은 2라는 공통 원소가 존재하기 때문에 서로소 관계가 아니다.
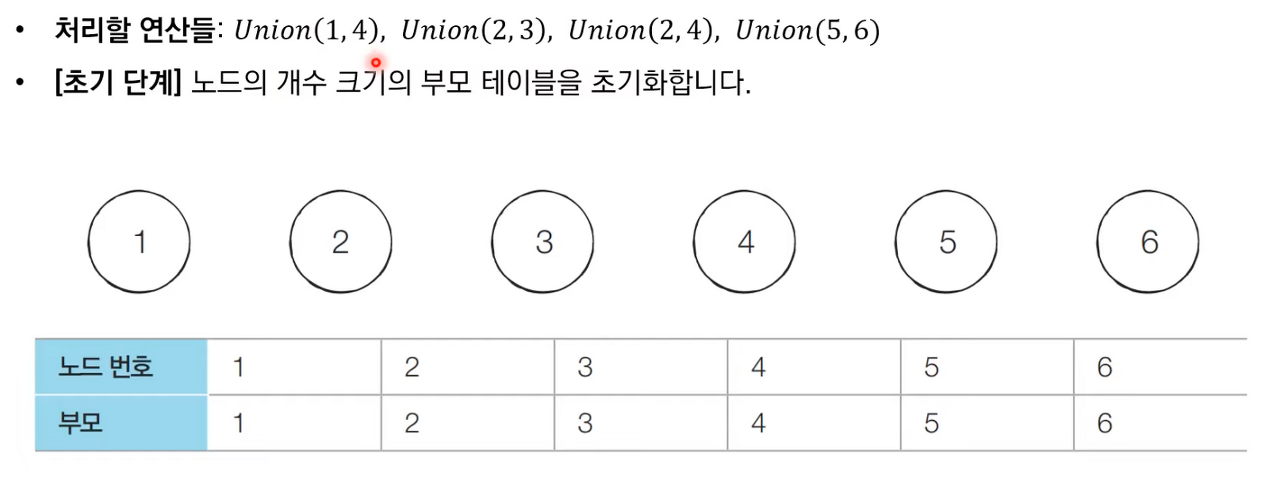
- 서로소 집합 자료구조: 서로소 부분 집합들로 나누어진 원소들의 데이터를 처리하기 위한 자료구조로 아래와 같이 두 종료의 연산을 지원한다. 지원하는 연산 때문에 합치기 찾기(Union Find) 자료 구조라고 불리기도 한다.
- 찾기(Find): 특정한 원소가 속한 집합이 어떤 집합인지 알려주는 연산
- 합집합(Union): 두 개의 원소가 포함된 집합을 하나의 집합으로 합치는 연산으로 동작 과정은 아래와 같다.
- 합집합(Union) 연산을 확인하여, 서로 연결된 두 노드 A, B를 확인한다
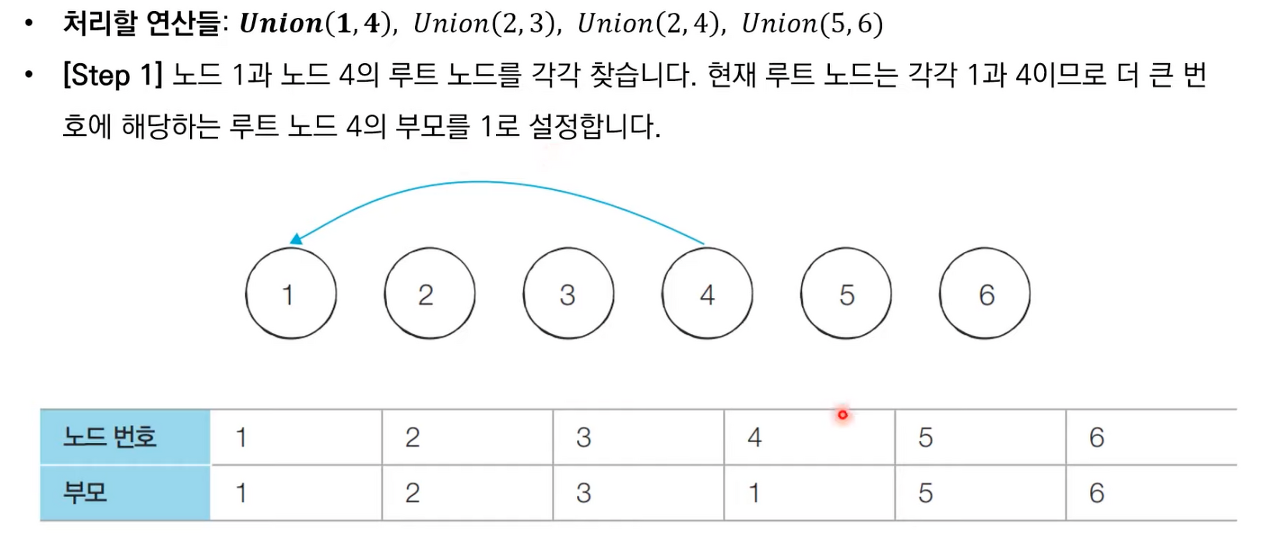
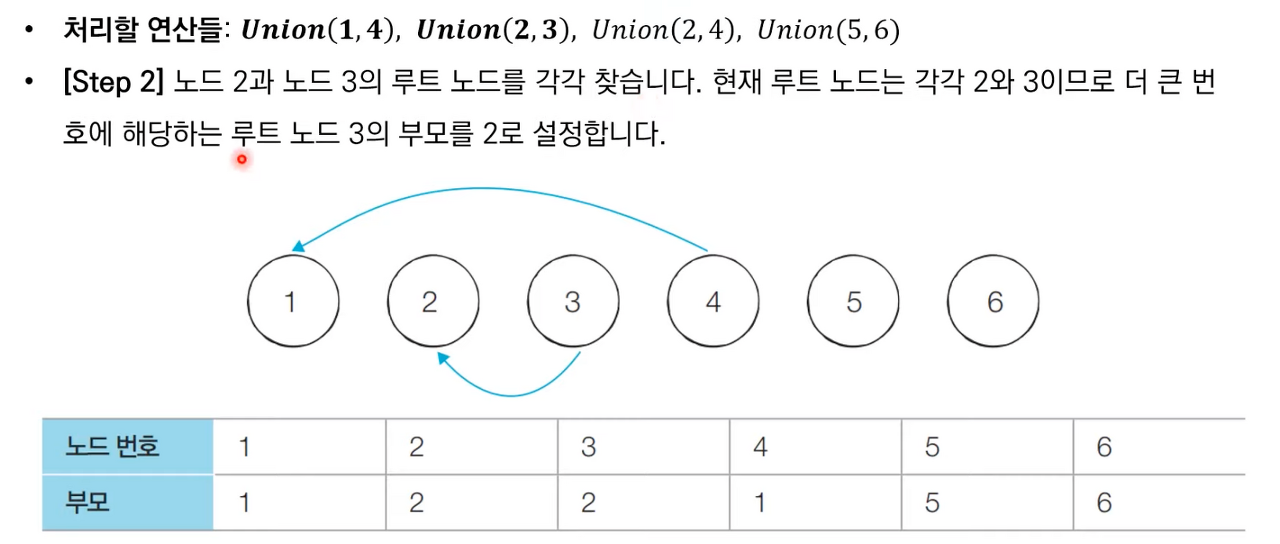
- A와 B의 루트 노드 A', B'를 각각 찾는다
- A'를 B'의 부모 노드로 설정한다.
- 모든 합집합(Union) 연산을 처리할 때까지 1번의 과정을 반복한다.
- 합집합(Union) 연산을 확인하여, 서로 연결된 두 노드 A, B를 확인한다
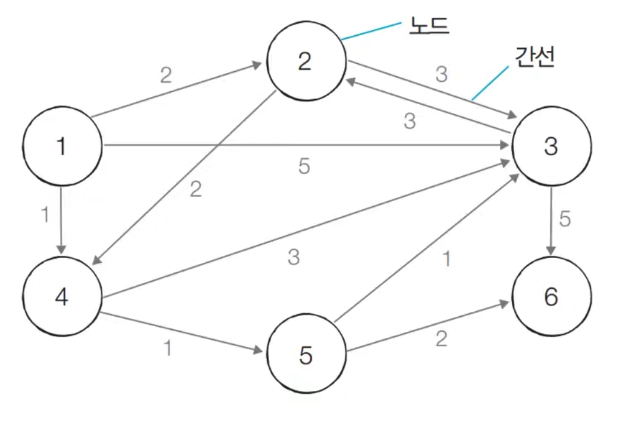
상세한 동작과정은 아래 이미지 참고 부탁드립니다.
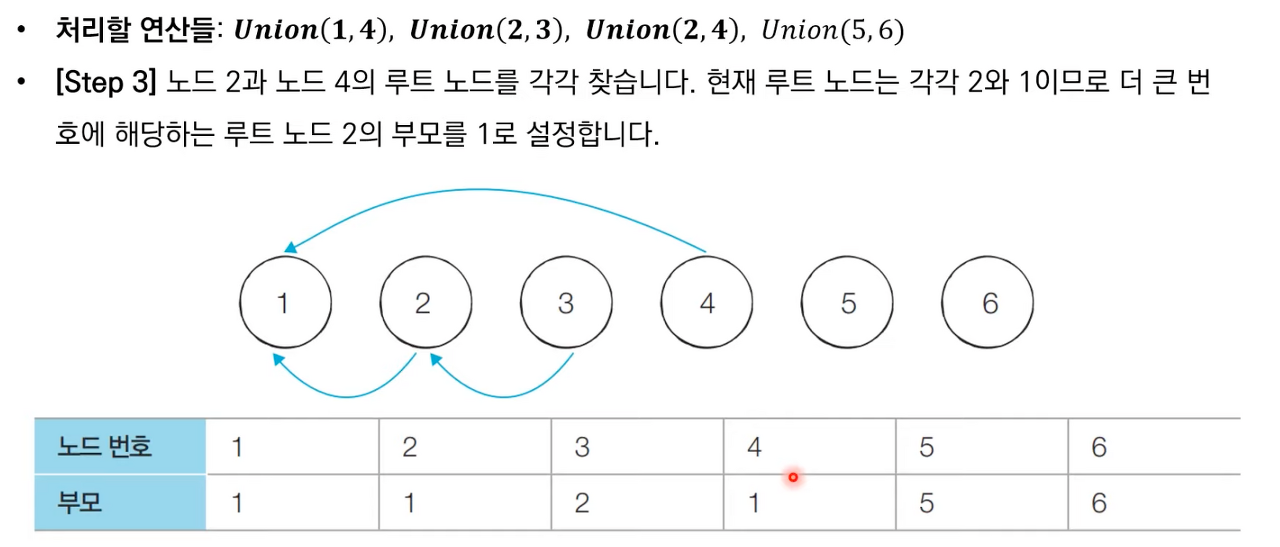
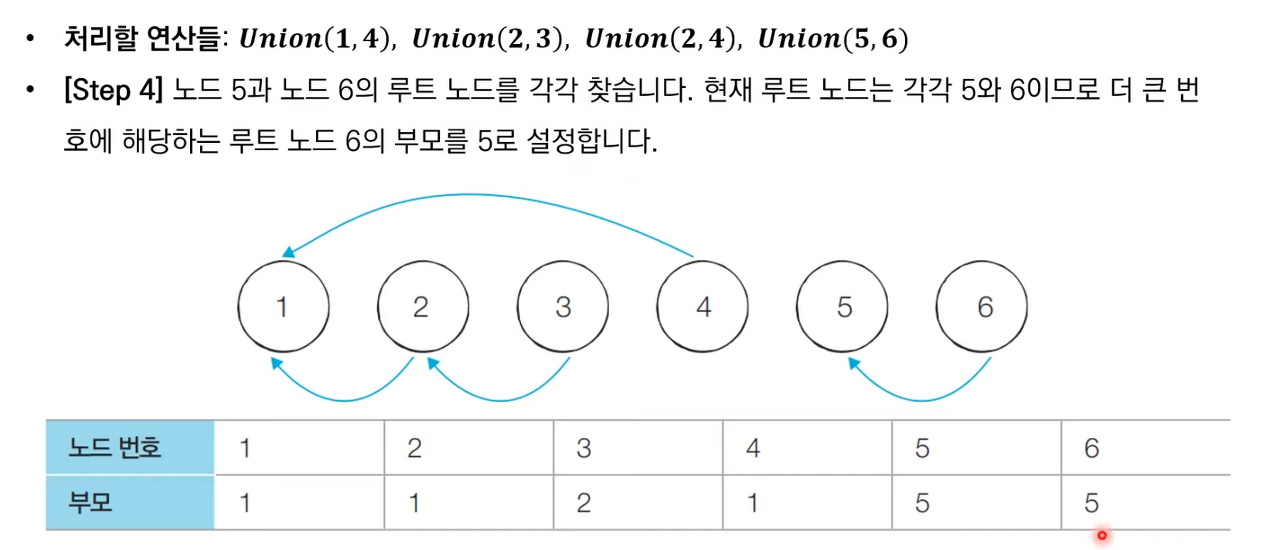
서로소 집합 알고리즘 소스 코드
import java.util.*;
public class Main
{
public static int[] parents;
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
int nodeCnt = scan.nextInt();
int edgeCnt = scan.nextInt();
parents = new int[nodeCnt + 1];
for(int i = 0; i < parents.length; i++){
parents[i] = i;
}
for(int i = 0; i < edgeCnt; i++){
int x = scan.nextInt();
int y = scan.nextInt();
unionParent(x, y);
}
System.out.print("각 원소가 속한 집합: ");
for(int i = 1; i < parents.length; i++){
System.out.print(findParent(i) + " ");
}
System.out.print("\n부모 테이블: ");
for(int i = 1; i < parents.length; i++){
System.out.print(parents[i] + " ");
}
}
public static void unionParent(int x, int y){
int rootX = findParent(x);
int rootY = findParent(y);
if(rootX < rootY){
parents[rootY] = rootX;
}else{
parents[rootX] = rootY;
}
}
public static int findParent(int node){
return (node == parents[node] ? node : findParent(parents[node]));
}
}
| 입력 예시 | |
| 6 4 1 4 2 3 2 4 5 6 |
|
| 출력 예시 | |
| 각 원소가 속한 집합: 1 1 1 1 5 5 부모 테이블: 1 1 2 1 5 5 |
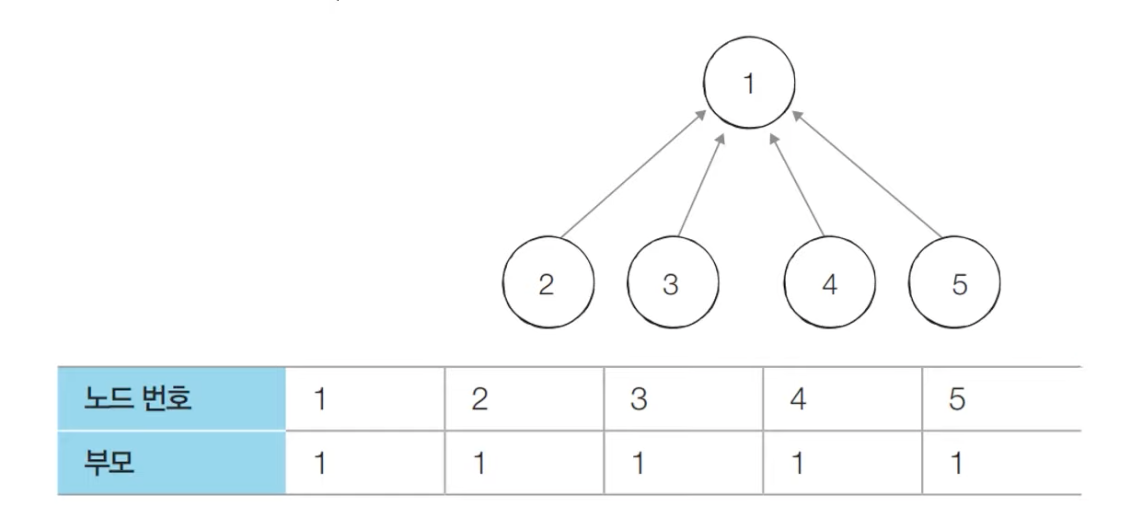
개선된 서로소 집합 알고리즘
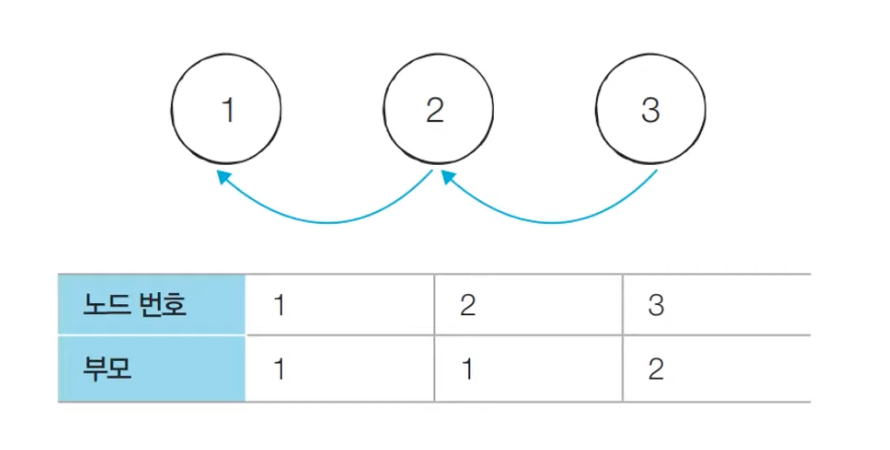
기본적인 서로소 집합 알고리즘 코드에서는 루트 노드에 즉시 접근 할 수가 없다. 위 그림처럼 노드 3의 루트를 찾기 위해서는 노드 2로 이동한 다음 노드 3의 부모를 또 확인해서 노드 1로 접근해야 한다. 다시 말해 서로로 집합 알고리즘으로 루트를 찾기 위해서는 재귀적으로 부모를 거슬러 올라가야 한다. 이렇게 구현하면 답을 구할 수는 있지만 find 함수가 비효율적으로 동작한다. 최악의 경우 find 함수가 모든 노드를 다 확인하는 터라 시간 복잡도가 O(V)라는 점이다. 결과적으로 기존 알고리즘을 그대로 이용하게 되면 노드의 개수가 V개이고 find 혹은 union 연산의 개수가 M개일 때 총 시간 복잡도는 O(VM)이 되어 비효율적이다. 이러한 find 함수를 경로 압축이라는 간단한 방법으로 최적화할 수 있다.
- 경로 압축(Path Compression): 찾기(Find) 함수를 재귀적으로 호출한 뒤에 부모 테이블 값을 바로 갱신하는 기법
public static int findParent(int node){
if(node != parents[node]) {
parents[node] = findParent(parents[node]);
}
return parents[node];
}경로 압출 기법을 적용하면 각 노드에 대하여 찾기(Find) 함수를 호출한 이후에 해당 노드의 루트 노드가 바로 부모 노드가 되어 기본적인 방법에 비하여 시간 복잡도가 개선된다.
개선된 서로소 집합 알고리즘 소스 코드
import java.util.*;
public class Main
{
public static int[] parents;
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
int nodeCnt = scan.nextInt();
int edgeCnt = scan.nextInt();
parents = new int[nodeCnt + 1];
for(int i = 0; i < parents.length; i++){
parents[i] = i;
}
for(int i = 0; i < edgeCnt; i++){
int x = scan.nextInt();
int y = scan.nextInt();
unionParent(x, y);
}
System.out.print("각 원소가 속한 집합: ");
for(int i = 1; i < parents.length; i++){
System.out.print(findParent(i) + " ");
}
System.out.print("\n부모 테이블: ");
for(int i = 1; i < parents.length; i++){
System.out.print(parents[i] + " ");
}
}
public static void unionParent(int x, int y){
int rootX = findParent(x);
int rootY = findParent(y);
if(rootX < rootY){
parents[rootY] = rootX;
}else{
parents[rootX] = rootY;
}
}
public static int findParent(int node){
if(node != parents[node]) {
parents[node] = findParent(parents[node]);
}
return parents[node];
}
}
| 입력 예시 | |
| 6 4 1 4 2 3 2 4 5 6 |
|
| 출력 예시 | |
| 각 원소가 속한 집합: 1 1 1 1 5 5 부모 테이블: 1 1 1 1 5 5 |
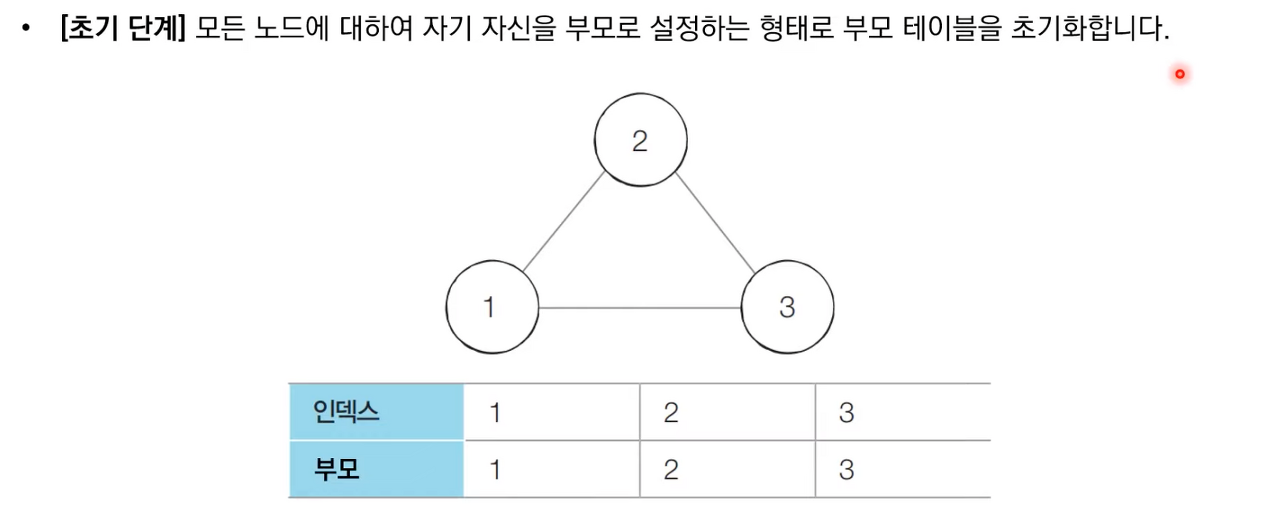
서로소 집합을 활용한 사이클 판별
서로소 집합은 다양한 알고리즘에 사용될 수 있는데 특히 무방향 그래프 내에서 사이클을 판별할 때 사용할 수 있다는 특징이 있다. 서로소 집합의 합치기(Union) 연산은 그래프에서 간선으로 표현될 수 있다. 따라서 간선을 하나씩 확인하면서 두 노드가 포함되어 있는 집합을 합치는 과정을 반복하는 것만으로도 사이클을 판별할 수 있다. 알고리즘은 다음과 같다.
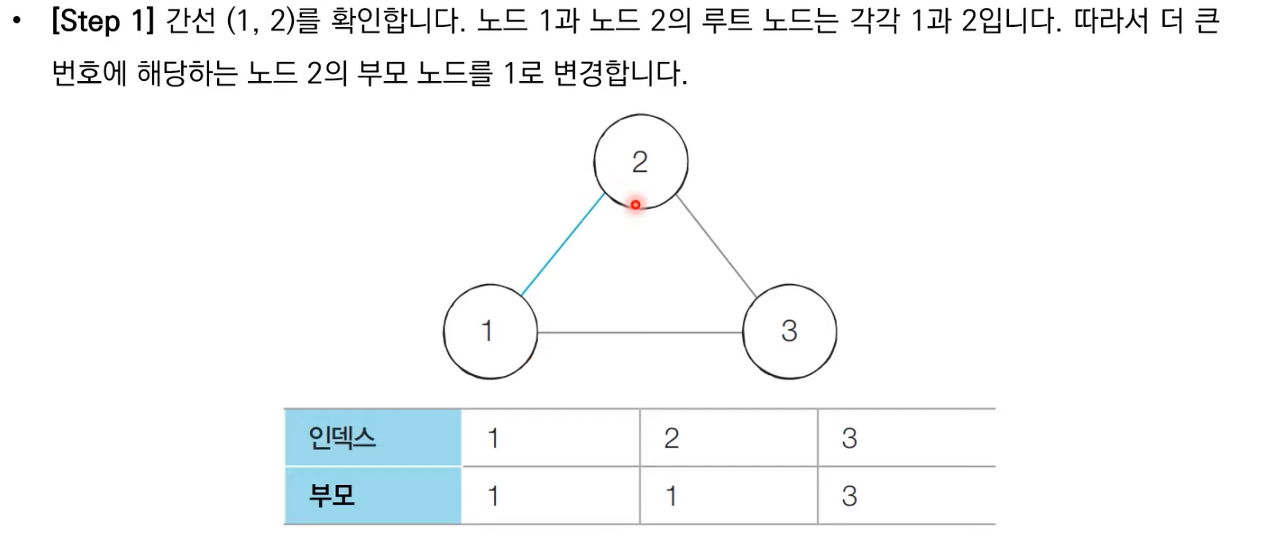
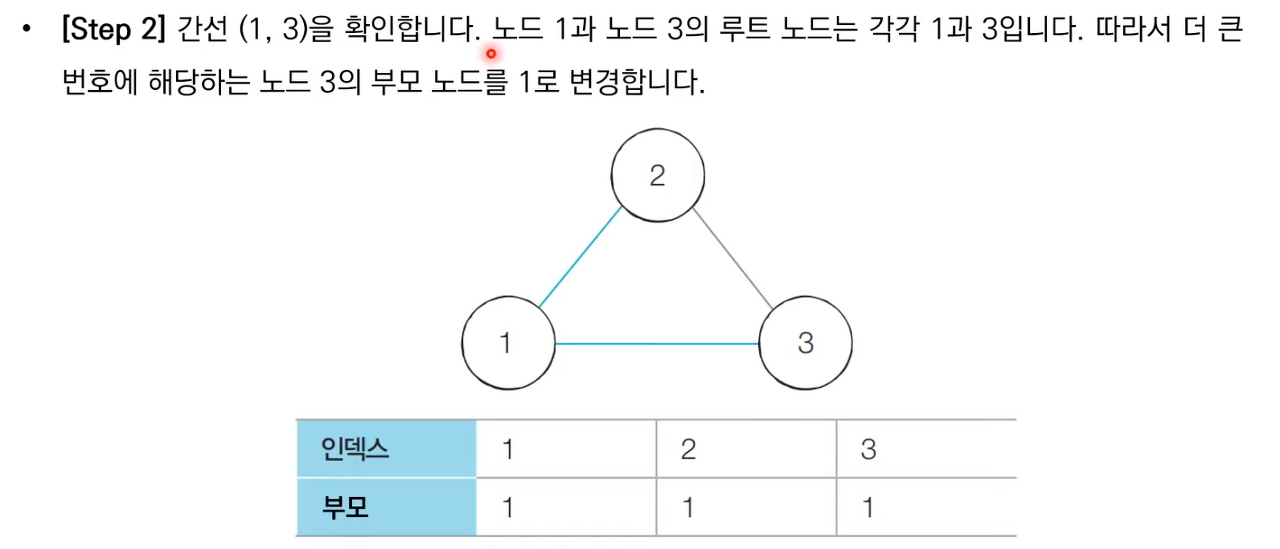
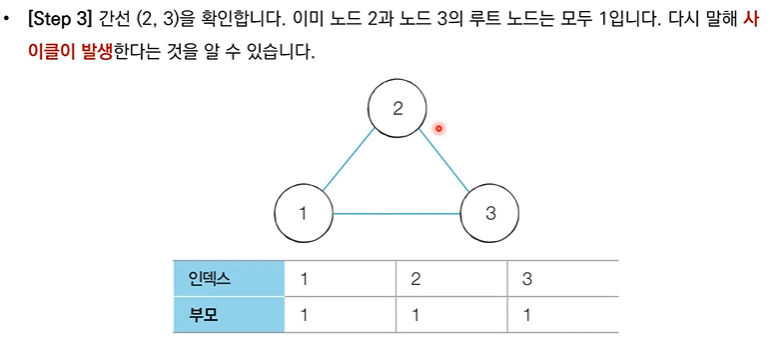
- 각 간선을 하나씩 확인하며 두 노드의 루트 노드를 확인한다.
- 루트 노드가 서로 다르다면 두 노드에 대하여 합집합(Union) 연산을 수행한다.
- 루트 노드가 서로 같다면 사이클(Cycle)이 발생한 것이다.
- 그래프에 포함되어 있는 모든 간선에 대하여 1번 과정을 반복한다.
상세한 동작과정은 아래 이미지 참고 부탁드립니다.
서로소 집합을 활용한 사이클 판별 소스 코드
import java.util.*;
public class Main
{
public static int[] parents;
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
int nodeCnt = scan.nextInt();
int edgeCnt = scan.nextInt();
boolean hasCycle = false;
parents = new int[nodeCnt + 1];
for(int i = 0; i < parents.length; i++){
parents[i] = i;
}
for(int i = 0; i < edgeCnt; i++){
int x = scan.nextInt();
int y = scan.nextInt();
if(findParent(x) == findParent(y)){
hasCycle = true;
break;
}
unionParent(x, y);
}
if (hasCycle) {
System.out.println("사이클이 발생했습니다.");
} else {
System.out.println("사이클이 발생하지 않았습니다.");
}
}
public static void unionParent(int x, int y){
int rootX = findParent(x);
int rootY = findParent(y);
if(rootX < rootY){
parents[y] = rootX;
}else{
parents[x] = rootY;
}
}
public static int findParent(int node){
// 루트 노드를 찾을 때까지 재귀 호출
if(node != parents[node]) {
parents[node] = findParent(parents[node]);
}
return parents[node];
}
}
| 입력 예시 | |
| 3 3 1 2 1 3 2 3 |
|
| 출력 예시 | |
| 사이클이 발생했습니다. |
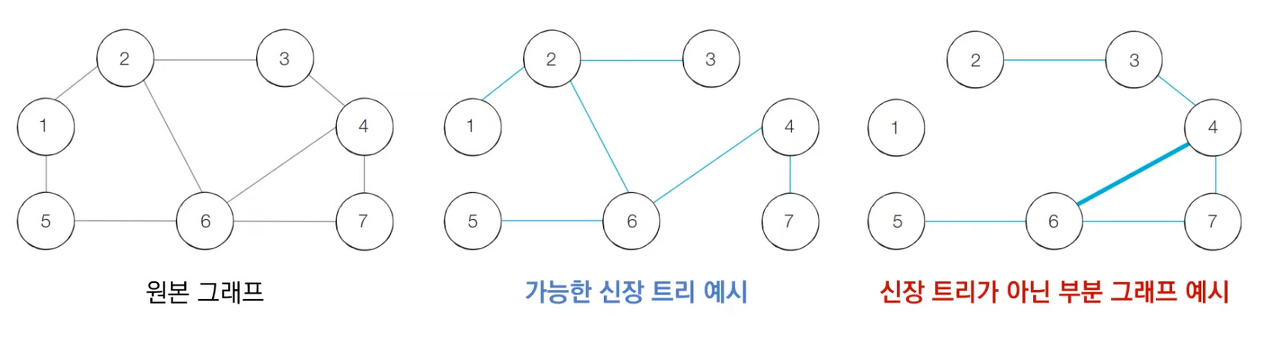
신장 트리
그래프 알고리즘 문제로 자주 출제되는 문제 유형으로 하나의 그래프가 있을 때 모든 노드를 포함하면서 사이클이 존재하지 않는 부분 그래프를 의미한다. 이때 모든 노드가 포함되어 서로 연결되면서 사이클이 존재하지 않는다는 조건은 트리의 조건이기도 하다. 그래서 이러한 그래프를 신장 트리라고 부르는 것이다. 우리는 다양한 문제 상황에서 가능한 한 최소한의 비용으로 신장 트리를 찾아야 할 때가 있는데 이런 문제 상황에 사용되는 알고리즘을 최소 신장 트리 알고리즘이라고 한다.
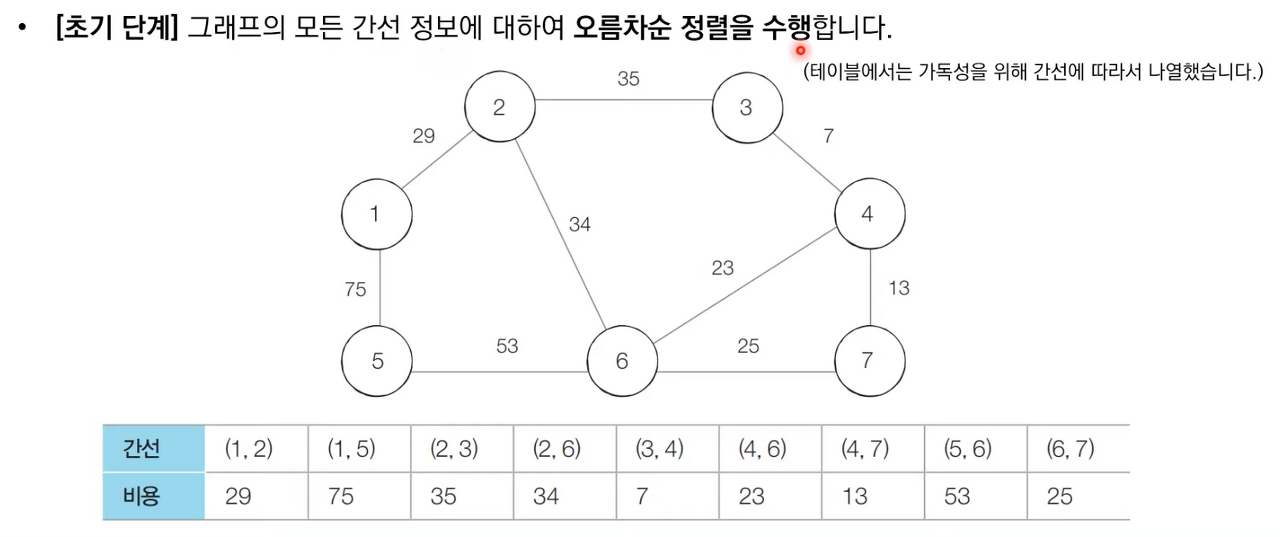
크루스칼 알고리즘 (Kruskal Algorithm)
대표적인 최소 신장 트리 알고리즘으로 그리디 알고리즘으로 분류된다. 먼저 모든 간선에 대하여 정렬을 수행한 뒤에 가장 거리가 짧은 간선부터 집합에 포함시키면 된다. 이때 사이클을 발생시킬 수 잇는 간선의 경우 집합에 포함시키지 않는다. 구체적인 알고리즘 순서는 다음과 같다.
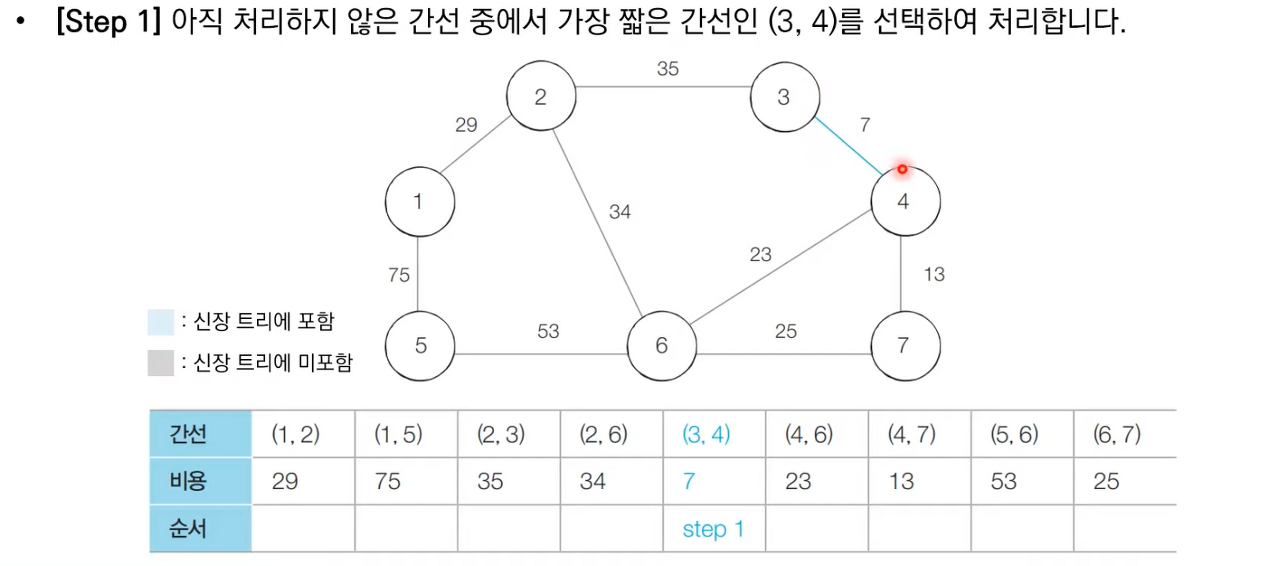
- 간선 데이터를 비용에 따라 오름차순으로 정렬한다.
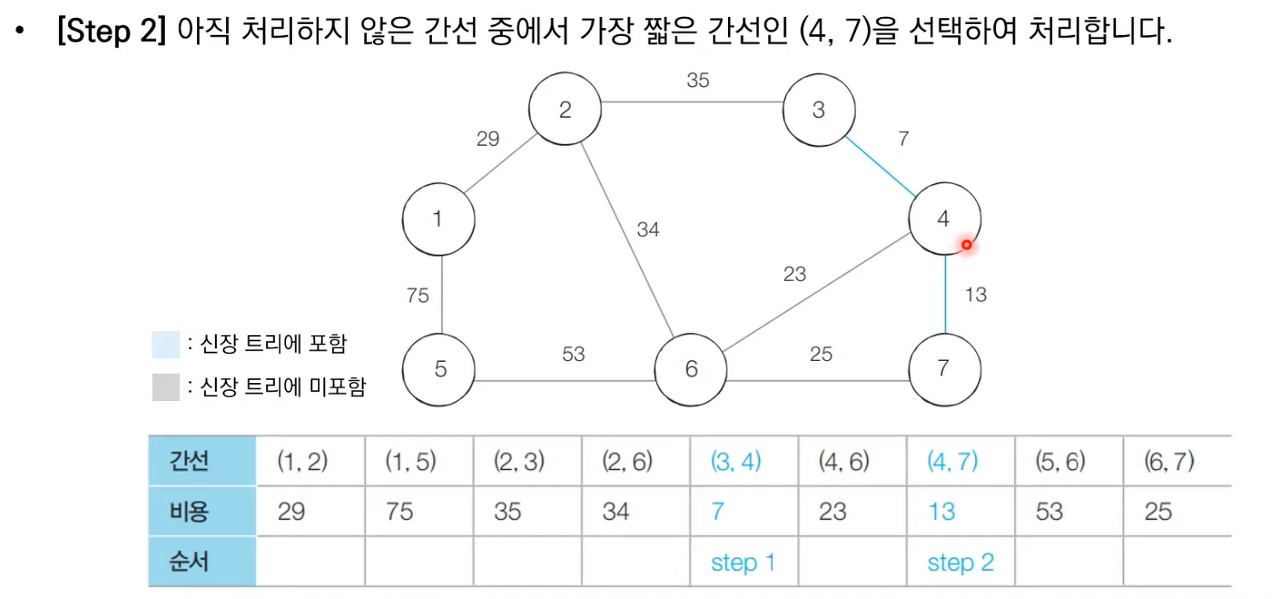
- 간선을 하나씩 확인하며 현재의 간선이 사이클을 발생시키는지 확인한다.
- 사이클이 발생하지 않는 경우 최소 신장 트리에 포함시킨다.
- 사이클이 발생하는 경우 최소 신장 트리에 포함시킨다.
- 모든 간선에 대하여 2번의 과정을 반복한다.
크루스칼 알고리즘의 시간 복잡도는 간선의 개수가 E개일 때 O(ElogE)의 시간 복잡도를 가진다. 해당 알고리즘에서 시간이 가장 오래 걸리는 부분이 간선을 정렬하는 작업이기 때문에 간선의 정렬 시간으로 복잡도를 가진다.
상세한 동작과정은 아래 이미지 참고 부탁드립니다.
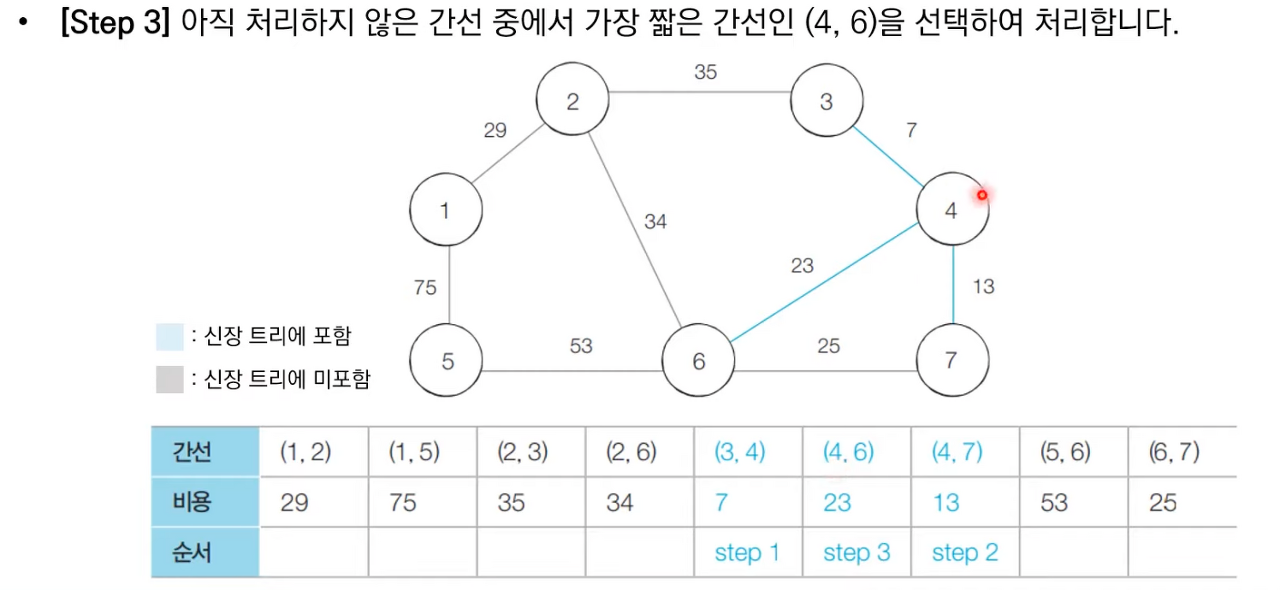
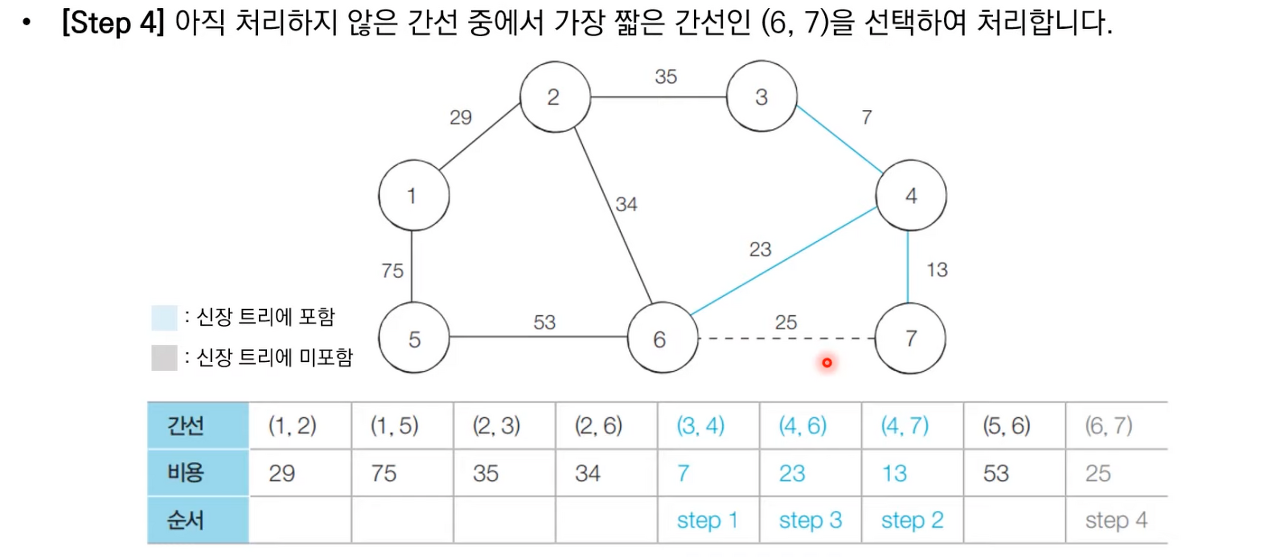
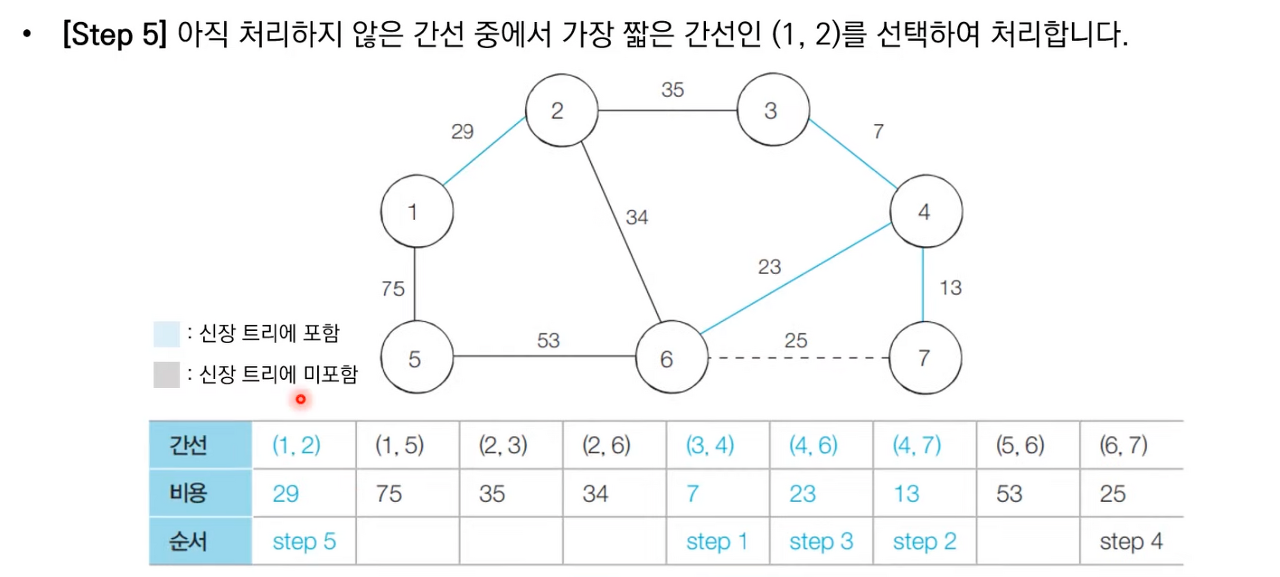
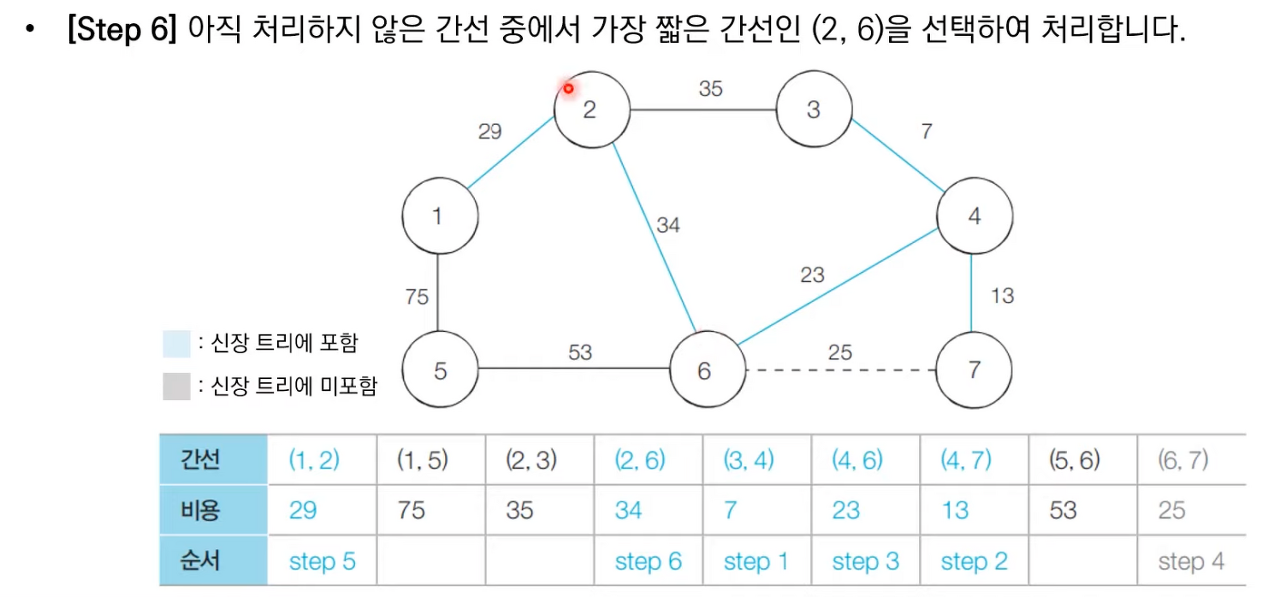
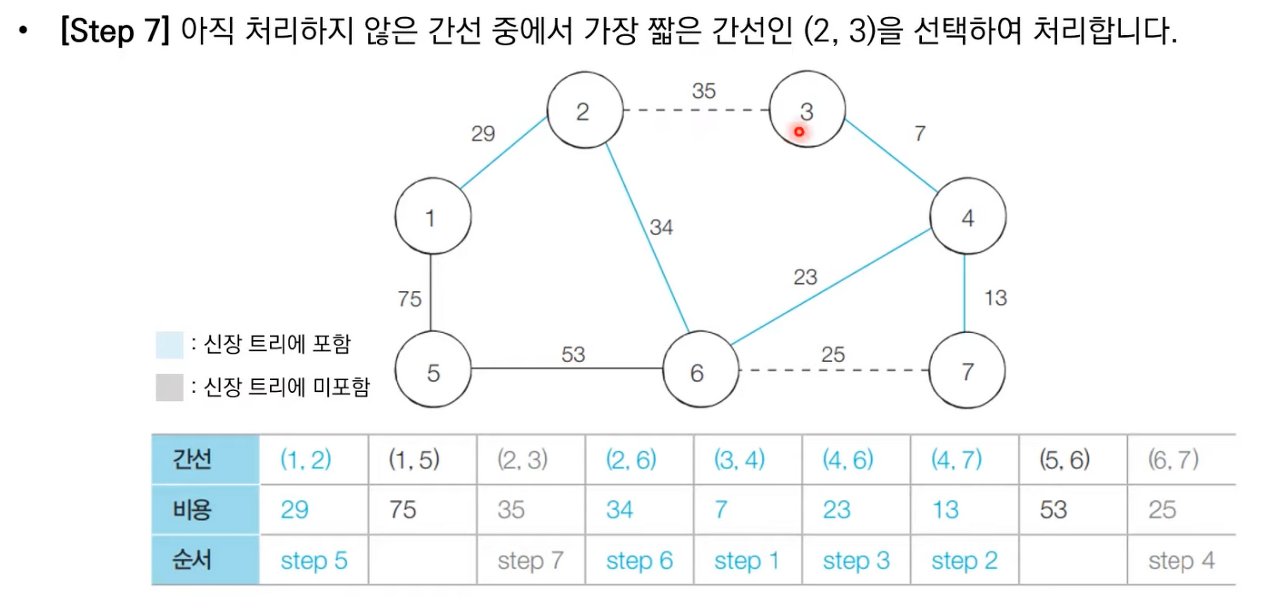
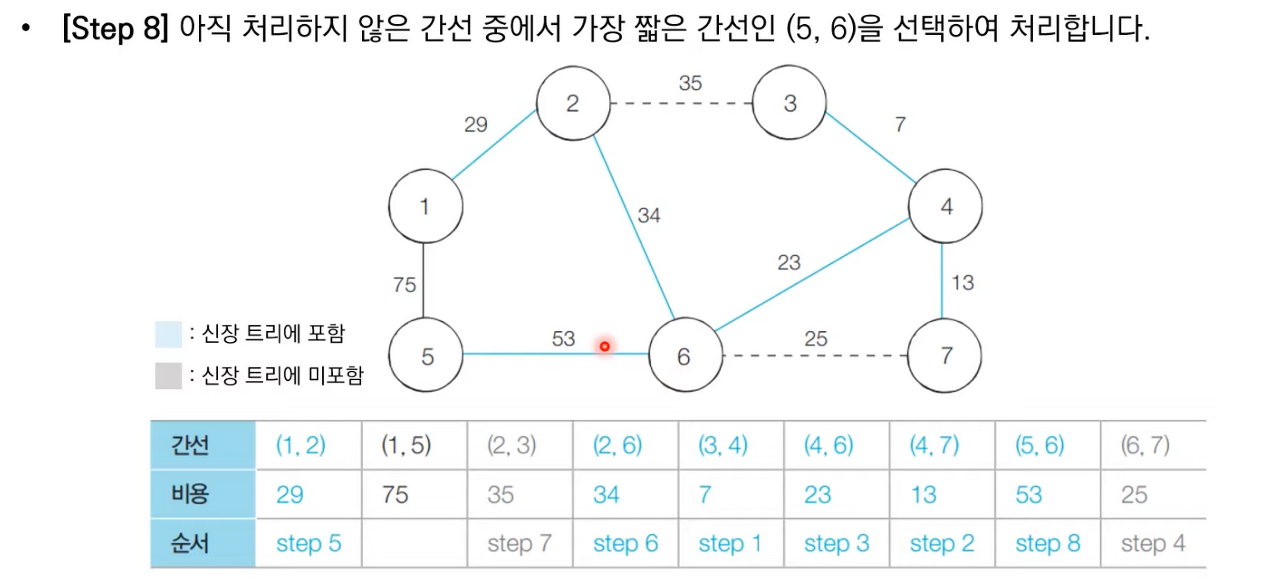
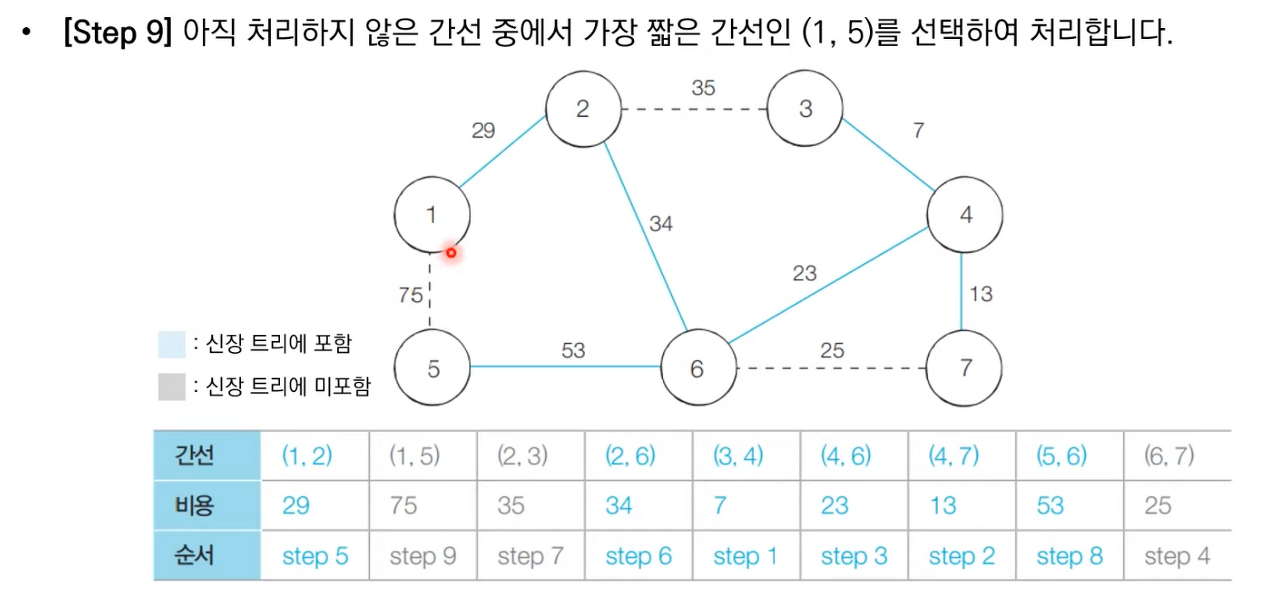
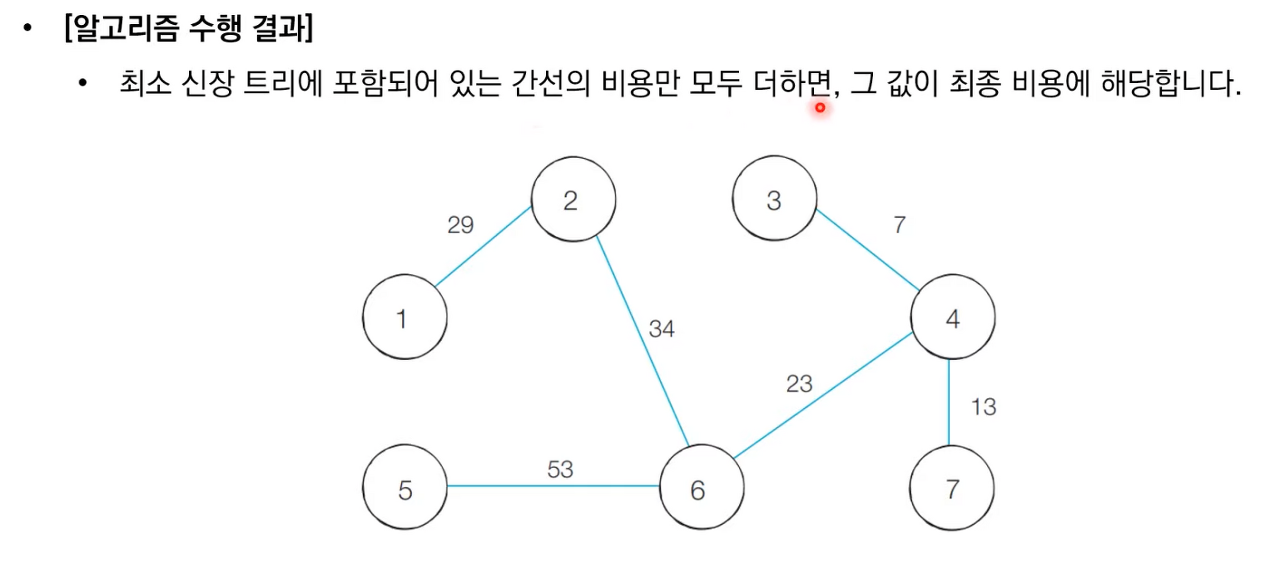
크루스칼 알고리즘 소스 코드
import java.util.*;
class Edge {
private int nodeX;
private int nodeY;
private int cost;
public Edge(int nodeX, int nodeY, int cost) {
this.nodeX = nodeX;
this.nodeY = nodeY;
this.cost = cost;
}
public int getNodeX() { return this.nodeX; }
public int getNodeY() { return this.nodeY; }
public int getCost() { return this.cost; }
}
public class Main
{
public static int[] parents;
public static ArrayList<Edge> edges = new ArrayList<>();
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
int nodeCnt = scan.nextInt();
int edgeCnt = scan.nextInt();
parents = new int[nodeCnt + 1];
for(int i = 0; i < parents.length; i++){
parents[i] = i;
}
for(int i = 0; i < edgeCnt; i++){
int x = scan.nextInt();
int y = scan.nextInt();
int cost = scan.nextInt();
edges.add(new Edge(x, y, cost));
}
edges.sort(Comparator.comparing(Edge::getCost));
int resultSum = 0;
for(Edge edge : edges){
int x = edge.getNodeX();
int y = edge.getNodeY();
//사이클이 생기는 경우 스킵
if (findParent(x) != findParent(y)) {
unionParent(x, y);
resultSum += edge.getCost();
}
}
System.out.println("result = " + resultSum);
}
public static void unionParent(int x, int y){
int rootX = findParent(x);
int rootY = findParent(y);
if(rootX < rootY){
parents[rootY] = rootX;
}else{
parents[rootX] = rootY;
}
}
public static int findParent(int node){
// 루트 노드를 찾을 때까지 재귀 호출
if(node != parents[node]) {
parents[node] = findParent(parents[node]);
}
return parents[node];
}
}
| 입력 예시 | 출력 예시 |
| 7 9 1 2 29 1 5 75 2 3 35 2 6 34 3 4 7 4 6 23 4 7 13 5 6 53 6 7 25 |
159 |
위상 정렬 (Topology Sort)
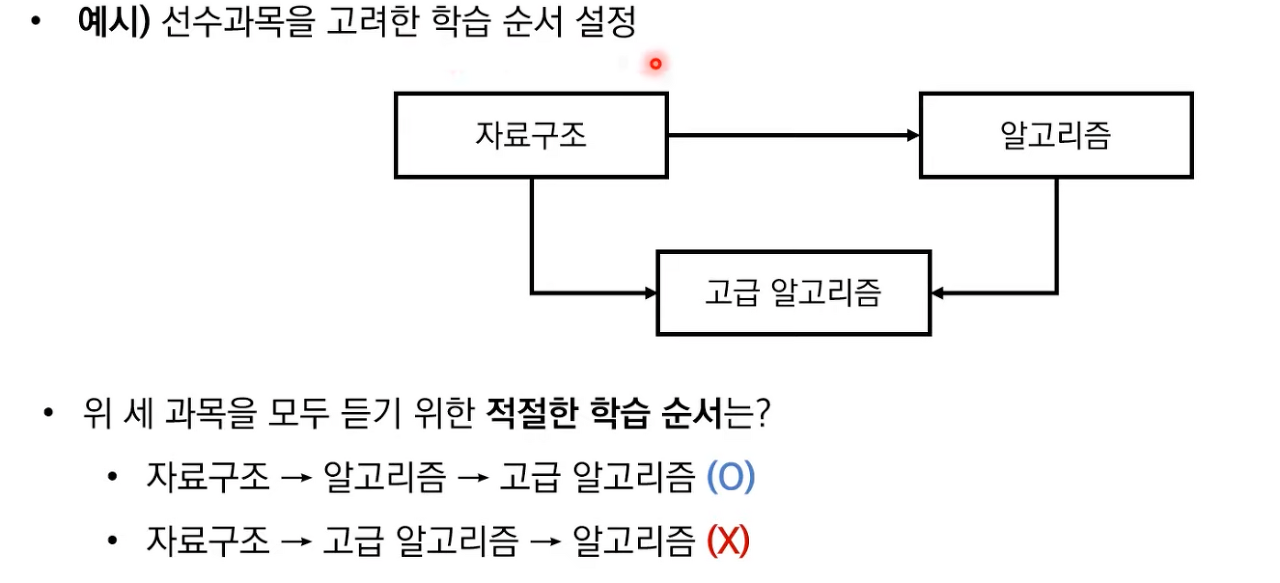
정렬 알고리즘의 일종으로 순서가 정해져 있는 일련의 작업을 차례대로 수행해야 할 때 사용할 수 있는 알고리즘이다. 즉 사이클이 없는 방향 그래프의 모든 노드를 방향성에 거스르지 않도록 순서대로 나열하는 것이다. 현실 세계의 전형적인 예시는 아래 그림과 같다. 위상 정렬은 순환하지 않는 방향 그래프(DAG, Direct Acyclic Graph)에 대해서만 수행할 수 있으며 모든 원소를 방문하기 전에 큐가 빈다면 사이클이 존재한다고 판단할 수 있다. 또한 위상 정렬을 수행할 때는 노드와 간선을 모두 확인해야 하기 때문에 O(V + E)의 시간 복잡도를 가진다.
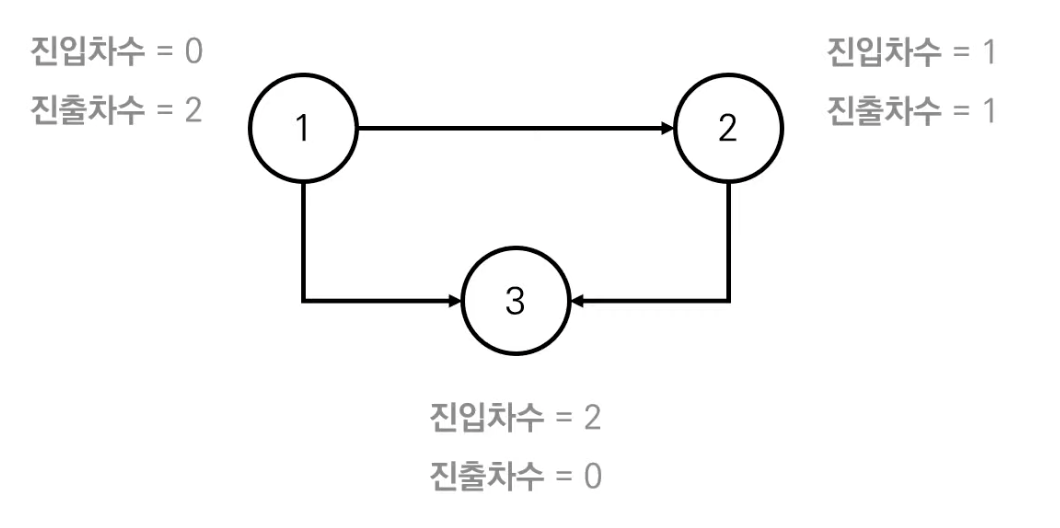
- 진입차수(Indegree): 특정한 노드로 들어오는 간선의 개수
- 진출차수(Outdegree): 특정한 노드에서 나가는 간선의 개수
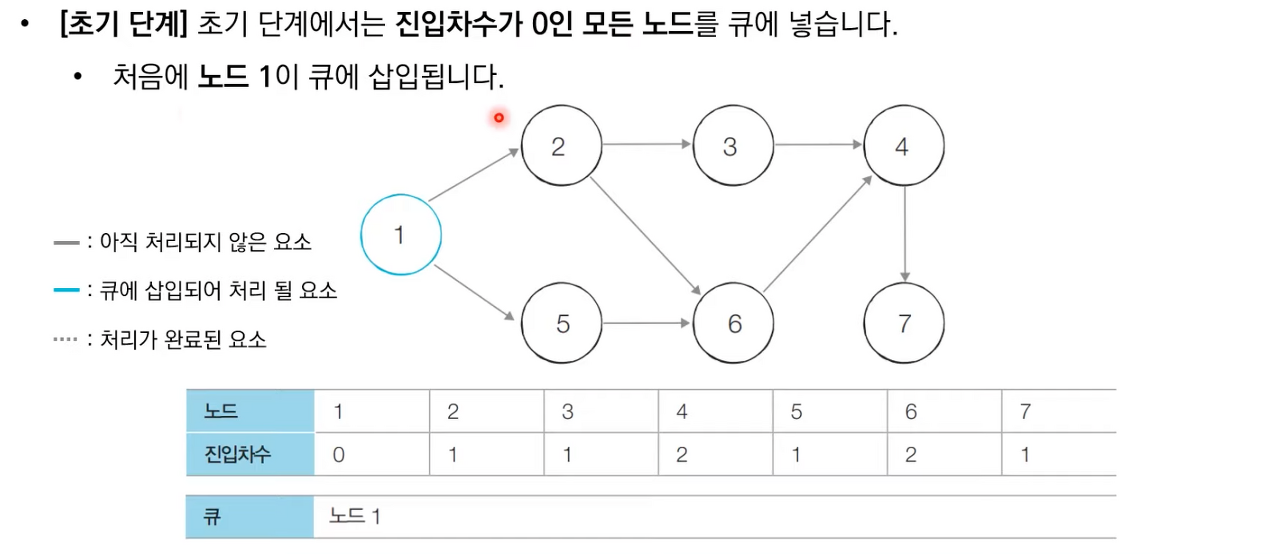
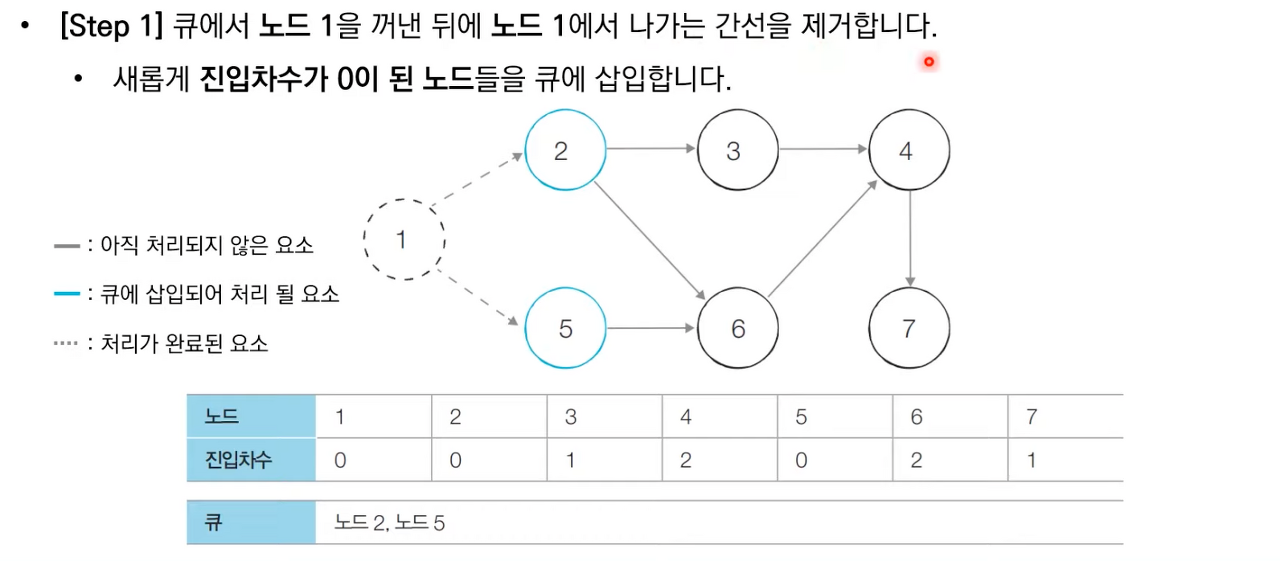
알고리즘은 다음과 같다.
- 진입차수가 0인 모든 노드를 큐에 넣는다.
- 큐가 빌 때까지 다음의 과정을 반복한다.
- 큐에서 원소를 꺼내 해당 노드에서 나가는 간선을 그래프에서 제거한다.
- 새롭게 진입차수가 0이 된 노드를 큐에 넣는다.
상세한 동작과정은 아래 이미지 참고 부탁드립니다.
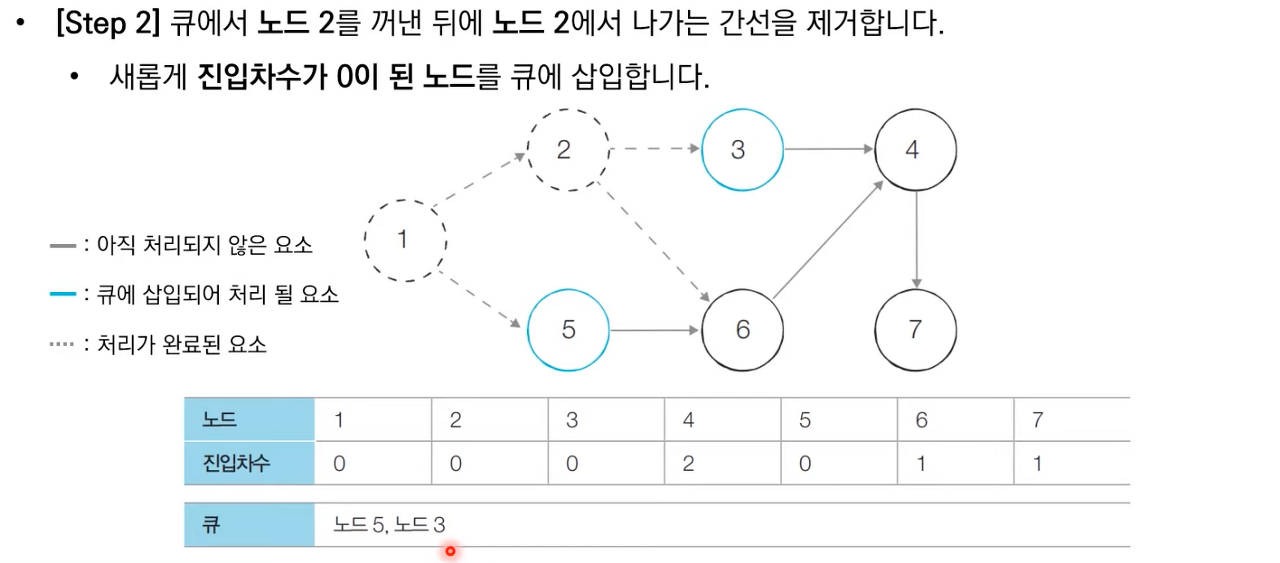
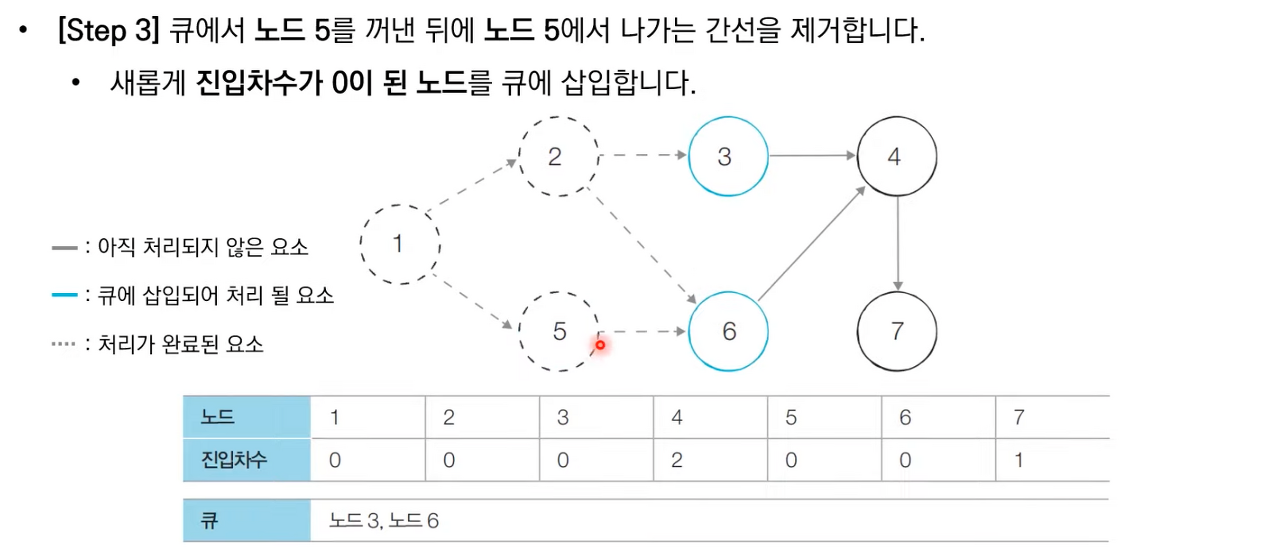
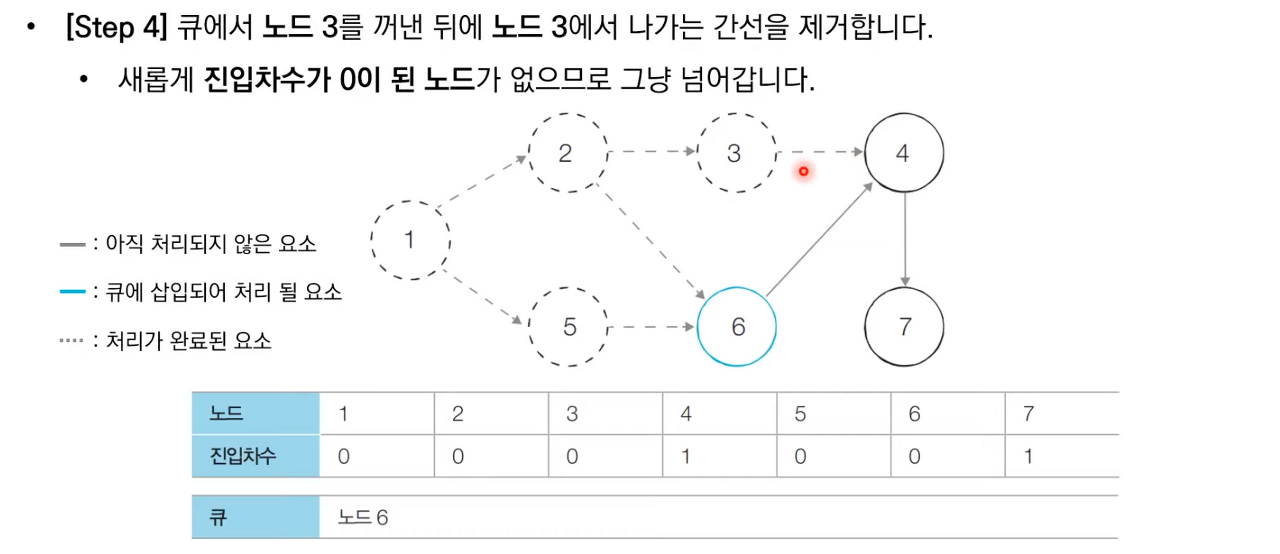
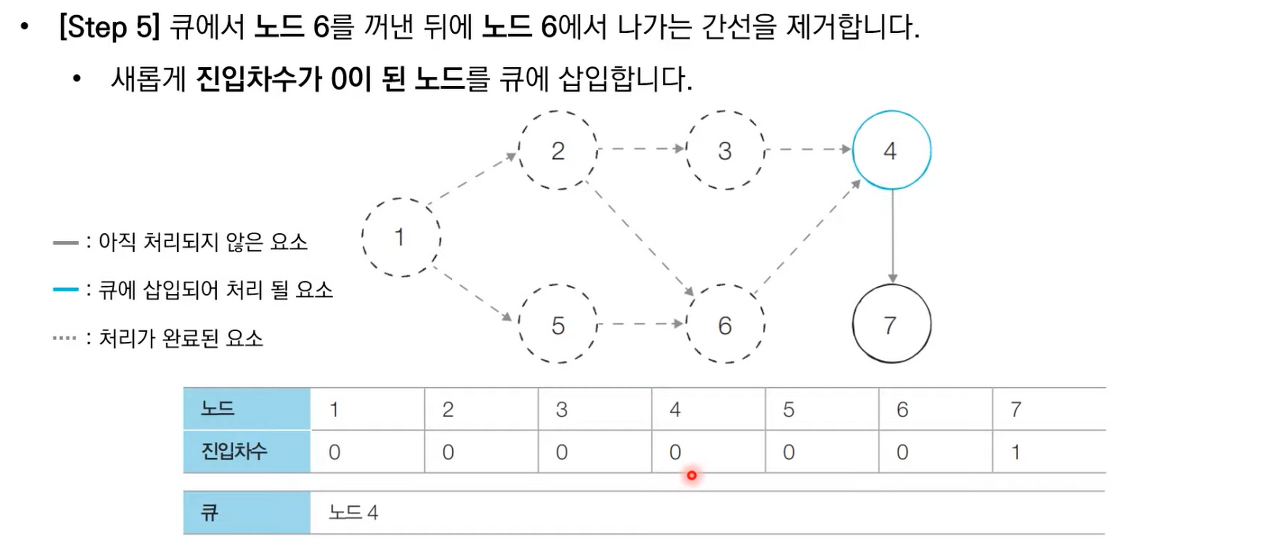
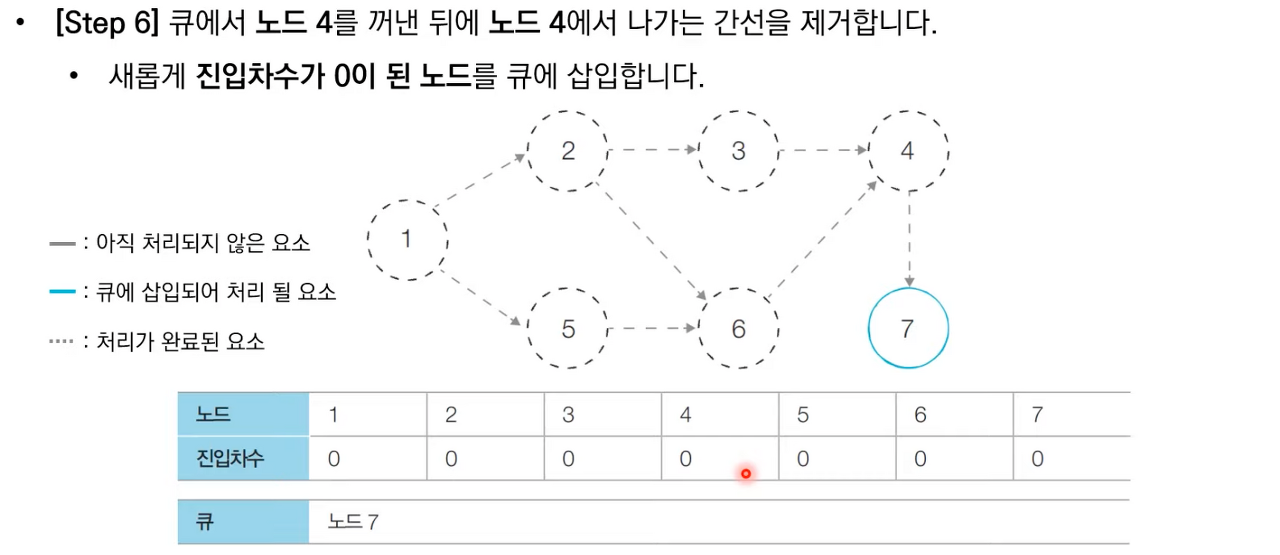
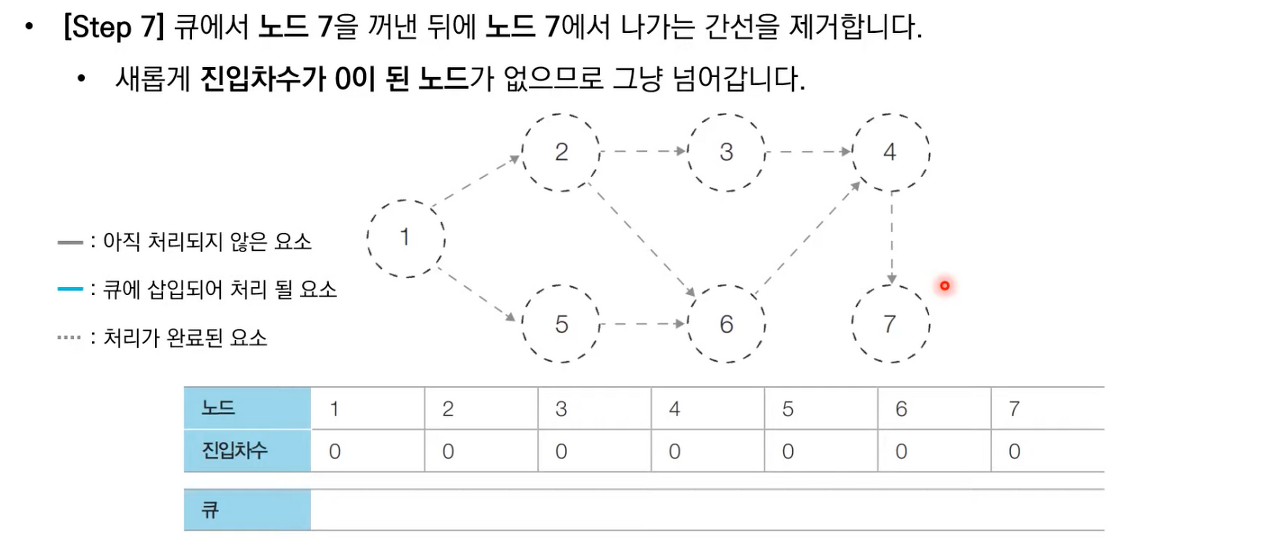
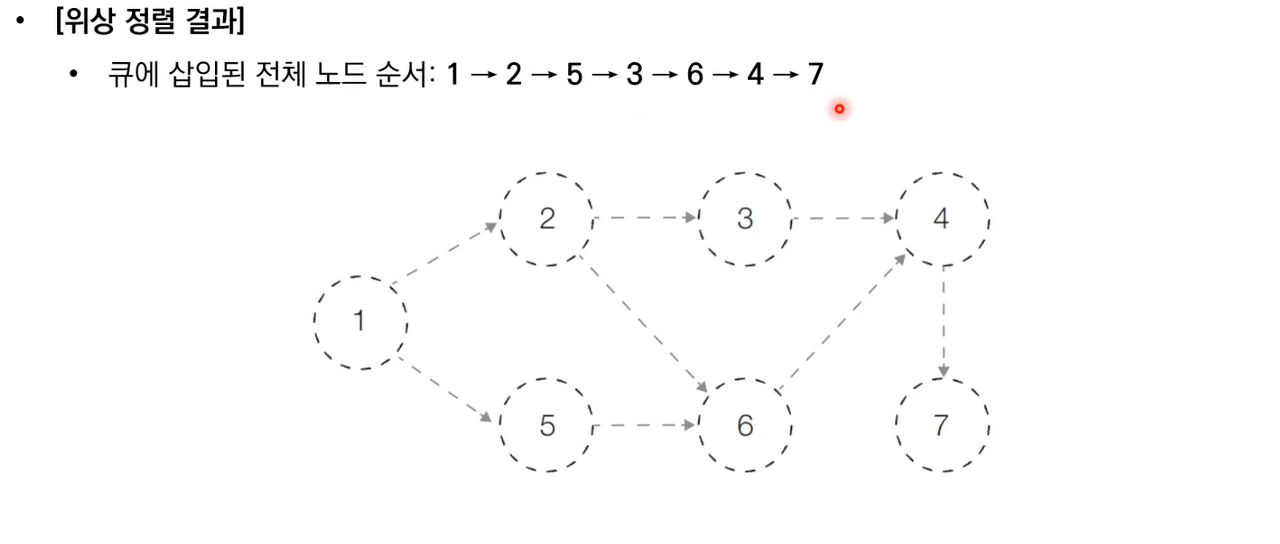
위상 정렬 소스 코드
import java.util.*;
public class Main
{
public static int nodeCnt;
public static int edgeCnt;
public static int[] indegree;
public static ArrayList<ArrayList<Integer>> graph = new ArrayList<>();
public static Queue<Integer> queue = new LinkedList<>();
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
nodeCnt = scan.nextInt();
edgeCnt = scan.nextInt();
indegree = new int[nodeCnt + 1];
for(int i = 0; i <= nodeCnt; i++){
graph.add(new ArrayList<Integer>());
}
for(int i = 0; i < edgeCnt; i++){
int x = scan.nextInt();
int y = scan.nextInt();
indegree[y]++;
graph.get(x).add(y);
}
topologySort();
}
public static void topologySort() {
for (int i = 1; i < indegree.length; i++) {
if (indegree[i] == 0) {
queue.offer(i);
}
}
while(!queue.isEmpty()){
int now = queue.poll();
System.out.print(now + " ");
for(Integer child : graph.get(now)){
indegree[child]--;
if(indegree[child] == 0){
queue.offer(child);
}
}
}
}
}
| 입력 예시 | 출력 예시 |
| 7 8 1 2 1 5 2 3 2 6 3 4 4 7 5 6 6 4 |
1 2 5 3 6 4 7 |
예제 1 - 팀 결성
난이도 ●●○ | 풀이 시간 20분 | 시간 제한 2초 | 메모리 제한 128MB | 핵심 유형
학교에서 학생들에게 0번부터 N번까지의 번호를 부여했다. 처음에는 모든 학생이 서로 다른 팀으로 구분되어, 총 N + 1 개의 팀이 존재한다. 이때 선생님은 '팀 합치기'연산과 '같은 팀 여부 확인'연산을 사용할 수 있다.
- '팀 합치기' 연산은 두 팀을 합치는 연산이다.
- '같은 팀 여부 확인' 연산은 특정한 두 학생이 같은 팀에 속하는지를 확인하는 연산이다.
선생님이 M개의 연산을 수행할 수 있을 때, '같은 팀 여부 확인'연산에 대한 연산 결과를 출력하는 프로그램을 작성하시오.
입력 조건
- 첫째 줄에 N, M이 주어진다. M은 입력으로 주어지는 연산의 개수이다. (1 <= N, M <= 100,000)
다음 M개의 줄에는 각각의 연산이 주어진다. - '팀 합치기' 연산은 0 a b 형태로 주어진다. 이는 a번 학생이 속한 팀과 b번 학생이 속한 팀을 합친다는 의미이다.
- '같은 팀 여부 확인' 연산은 1 a b 형태로 주어진다. 이는 a번 학생과 b번 학생이 같은 팀에 속해 있는지를 확인하는 연산이다.
- a와 b는 N 이하의 양의 정수이다.
출력 조건
- '같은 팀 여부 확인'연산에 대하여 한 줄에 하나씩 YES 혹은 NO로 결과를 출력한다.
입력/출력 예시
| 입력 예시 | 출력 예시 |
| 7 8 0 1 3 1 1 7 0 7 6 1 7 1 0 3 7 0 4 2 0 1 1 1 1 1 |
NO NO YES |
요점
- 전형적인 서로소 집합 알고리즘 문제이다.
- N과 M의 범위가 모두 최대 100,000이기 때문에 경로 압축을 이용한 개선된 알고리즘을 사용해야 한다.
소스 코드
import java.util.*;
public class Main
{
public static int[] parents;
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
int nodeCnt = scan.nextInt();
int edgeCnt = scan.nextInt();
StringBuffer result = new StringBuffer();
parents = new int[nodeCnt + 1];
for(int i = 1; i < parents.length; i++){
parents[i] = i;
}
for(int i = 0; i < edgeCnt; i++){
int action = scan.nextInt();
int x = scan.nextInt();
int y = scan.nextInt();
if(action == 0){
unionTeam(x, y);
}else if(action == 1){
result.append(findTeam(x) == findTeam(y) ? "YES" : "NO");
result.append("\n");
}
}
System.out.println(result.toString());
}
public static void unionTeam(int x, int y) {
int rootX = findTeam(x);
int rootY = findTeam(y);
if(rootX < rootY){ parents[rootX] = rootY; }
else { parents[rootY] = rootY; }
}
public static int findTeam(int team) {
if(team != parents[team]){
parents[team] = findTeam(parents[team]);
}
return parents[team];
}
}
예제 2 - 도시 분할 계획
난이도 ●●○ | 풀이 시간 40분 | 시간 제한 2초 | 메모리 제한 256MB | 기초 문제집
동물원에서 막 탈출한 원숭이 한 마리가 세상 구경을 하고 있다. 어느 날 원숭이는 '평화로운 마을'에 잠시 머물렀는데 마침 마을 사람들은 도로 공사 문제로 머리를 맞대고 회의 중이었다.
마을은 N개의 집과 그 집들을 연결하는 M개의 길로 이루어져 있다. 길은 어느 방향으로든지 다닐 수 있는 편리한 길이다. 그리고 길마다 길을 유지하는데 드는 유지비가 있다.
마을의 이장은 마을을 2개의 분리된 마을로 분할할 계획을 세우고 있다. 마을이 너무 커서 혼자서는 관리할 수 없기 때문이다. 마을을 분할할 때는 각 분리된 마을 안에 집들이 서로 연결되도록 분할해야 한다. 각 분리된 마을 안에 있는 임의의 두 집 사이에 경로가 항상 존재해야 한다는 뜻이다. 마을에는 집이 하나 이상 있어야 한다.
그렇게 마을의 이장은 계획을 세우다가 마을 안에 길이 너무 많다는 생각을 하게 되었다. 일단 분리된 두 마을 사이에 있는 길들은 필요가 없으므로 없앨 수 있다. 그리고 각 분리된 마을 안에서도 임의의 두 집 사이에 경로가 항상 존재하게 하면서 길을 더 없앨 수 있다. 마을의 이장은 위 조건을 만족하도록 길들을 모두 없애고 나머지 길의 유지비의 합을 최소로 하고 싶다. 이것을 구하는 프로그램을 작성하시오.
입력 조건
- 첫째 줄에 집의 개수 N, 길의 개수 M이 주어진다. N은 2 이상 100,000 이하인 정수이고, M은 1 이상 1,000,000 이하인 정수이다.
- 그 다음 줄부터 M줄에 걸쳐 길의 정보가 A, B, C 3개의 정수로 공백으로 구분되어 주어지는데 A번 집과 B번 집을 연결하는 길의 유지비가 C(1 <= C <= 1,000) 라는 뜻이다.
출력 조건
- 첫째 줄에 길을 없애고 남은 유지비 합의 최솟값을 출력한다.
입력/출력 예시
| 입력 예시 | 출력 예시 |
| 7 12 1 2 3 1 3 2 3 2 1 2 5 2 3 4 4 7 3 6 5 1 5 1 6 2 6 4 1 6 5 3 4 5 3 6 7 4 |
8 |
요점
- 전체 그래프에서 2개의 최소 신장 트리를 만들어야 한다.
- 크루스칼 알고리즘으로 최소 신장 트리를 찾은 뒤에 가장 비용이 큰 간선을 제거한다.
소스 코드
import java.util.*;
class Edge{
int cityA;
int cityB;
int cost;
public Edge(int cityA, int cityB, int cost){
this.cityA = cityA;
this.cityB = cityB;
this.cost = cost;
}
public int getCityA(){ return this.cityA; }
public int getCityB(){ return this.cityB; }
public int getCost(){ return this.cost; }
}
public class Main
{
public static int[] parents;
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
int nodeCnt = scan.nextInt();
int edgeCnt = scan.nextInt();
parents = new int[nodeCnt + 1];
ArrayList<Edge> edges = new ArrayList<>();
for(int i = 1; i <= nodeCnt; i++){
parents[i] = i;
}
for(int i = 1; i <= edgeCnt; i++){
int cityA = scan.nextInt();
int cityB = scan.nextInt();
int cost = scan.nextInt();
edges.add(new Edge(cityA, cityB, cost));
}
edges.sort(Comparator.comparing(Edge::getCost));
int resultSum = 0;
int maxCost = -1;
for(Edge edge : edges){
int cityA = edge.getCityA();
int cityB = edge.getCityB();
int cost = edge.getCost();
if(findParent(cityA) == findParent(cityB)) continue;
unionParent(cityA, cityB);
resultSum += cost;
maxCost = Math.max(maxCost, cost);
}
System.out.println("result = " + (resultSum - maxCost));
}
public static void unionParent(int a, int b){
int rootA = findParent(a);
int rootB = findParent(b);
if(rootA < rootB){
parents[rootA] = rootB;
} else {
parents[rootB] = rootA;
}
}
public static int findParent(int city){
if(city != parents[city]) {
parents[city] = findParent(parents[city]);
}
return parents[city];
}
}
예제 3 - 커리큘럼
난이도 ●●● | 풀이 시간 50분 | 시간 제한 2초 | 메모리 제한 128MB | 핵심 유형
동빈이는 온라인으로 컴퓨터 공학 강의를 듣고 있다. 이때 각 온라인 강의는 선수 강의가 있을 수 있는데, 선수 강의가 있는 강의는 선수 강의를 먼저 들어야만 해당 강의를 들을 수 있다. 동빈이는 총 N개의 강의를 듣고자 한다. 강의는 1번부터 N번까지의 번호를 가진다. 또한 동시에 여러 개의 강의를 들을 수 있다고 가정한다. 예를 들어, N = 3일 때, 3번 강의의 선수 강의로 1번과 2번 강의가 있고, 1번과 2번 강의는 선수 강의가 없다고 하자. 그리고 각 강의에 대하여 강의 시간이 다음과 같다고 하자.
1번 강의: 30시간
2번 강의: 20시간
3번 강의: 40시간
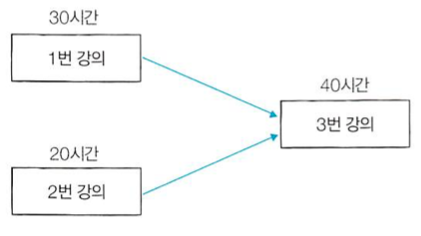
이 경우, 1번 강의를 수강하기까지의 최소 시간은 30시간, 2번 강의를 수강하기까지는 최소 20시간, 3번 강의를 수강하기까지는 최소 70시간이 필요하다. 동빈이가 듣고자 하는 N개의 강의 정보가 주어졌을 때, N개의 강의에 대하여 수강하기까지는 걸리는 최소 시간을 출력하는 프로그램을 작성해라.
입력 조건
- 첫째줄에 동빈이가 듣고자 하는 강의의 수 N(1 <= N <= 500)이 주어진다.
- 다음 N개의 줄에는 각 강의의 강의시간과 그 강의를 듣기 위해 먼저 들어야 하는 강의들의 번호가 자연수로 주어지며, 각 자연수는 공백으로 구분된다. 이 때 강의 시간은 100,000 이하의 자연수이다.
- 각 강의 번호는 1부터 N까지로 구성되며, 각 줄은 -1로 끝난다.
출력 조건
- N개의 강의에 대해 수강하기까지 걸리는 최소 시간을 한 줄에 하나씩 출력한다.
입력/출력 예시
| 입력 예시 | 출력 예시 |
| 5 10 -1 10 1 -1 4 1 -1 4 3 1 -1 3 3 -1 |
10 20 14 18 17 |
요점
- 위상 정렬 알고리즘의 응용 문제이다.
- 인접한 노드에 대하여 현재보다 강의 시간이 더 긴 경우를 찾는다면, 더 오랜 시간이 걸리는 경우의 시간 값을 저장하는 방식으로 결과 테이블을 갱신한다.
소스 코드
import java.util.*;
public class Main
{
public static int nodeCnt;
public static int[] time;
public static int[] input;
public static ArrayList<ArrayList<Integer>> required= new ArrayList<>();
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
nodeCnt = scan.nextInt();
time = new int[nodeCnt + 1];
input = new int[nodeCnt + 1];
for(int i = 0; i <= nodeCnt; i++){
required.add(new ArrayList<Integer>());
if(i != 0){
time[i] = scan.nextInt();
while(true){
int x = scan.nextInt();
if(x == -1){ break; }
input[i]++;
required.get(x).add(i);
}
}
}
topologySort();
}
public static void topologySort(){
int[] result = Arrays.copyOf(time, nodeCnt+1);
Queue<Integer> queue = new LinkedList<>();
for(int i = 1 ; i <= nodeCnt; i++){
if(input[i] == 0){
queue.offer(i);
}
}
while(!queue.isEmpty()){
int now = queue.poll();
for(Integer subject : required.get(now)){
result[subject] = Math.max(result[subject], result[now] + time[subject]);
input[subject]--;
if(input[subject] == 0){
queue.offer(subject);
}
}
}
Arrays.stream(result).skip(1).forEach(System.out::println);
}
}
그래프 이론 예제를 풀어본 후
정말 세상에는 똑똑한 사람이 정말 많은 것 같다. 다들 이런 알고리즘을 어떻게 생각해냈는지 만들고 되게 기분이 좋으셨을 것 같다. 이번에도 최단 경로처럼 이해하는데 큰 어려움은 없었는데 서로수 집합 알고리즘의 경우 대체 어느 상황에 쓰는 알고리즘인지 잘 모르겠다. 사이클을 찾는 용도로만 쓰기에는 좀 아쉬운 것 같은데 예제로 나온 문제도 단순히 서로수 집합 알고리즘을 그래도 말로 풀어놓은 것 같은 예제라 아쉬운 마음이 든다. 다음에 서로수 집합 예제를 한번 더 찾아봐야겠다.
GitHub: https://github.com/Leeyeonjae/coding-test/tree/main/10_Graph
참고서적 : 이것이 취업을 위한 코딩 테스트다 with 파이썬 by 나동빈
그래프 이론(Graph Theory)
그래프
노드(Node)와 노드 사이에 연결된 간선(Edge)의 정보를 가지고 있는 자료구조로 인접 행렬(2차원 배열 사용)과 인접 리스트(리스트 사용)를 이용해서 구현할 수 있다.
서로소 집합(Disjoint Sets)
공통 원소가 없는 두 집합이다. 예를 들어 집합 {1, 2}와 집합 {3, 4}는 서로소 관계이다. 반면에 집합 {1, 2}와 집합 {2, 3}은 2라는 공통 원소가 존재하기 때문에 서로소 관계가 아니다.
- 서로소 집합 자료구조: 서로소 부분 집합들로 나누어진 원소들의 데이터를 처리하기 위한 자료구조로 아래와 같이 두 종료의 연산을 지원한다. 지원하는 연산 때문에 합치기 찾기(Union Find) 자료 구조라고 불리기도 한다.
- 찾기(Find): 특정한 원소가 속한 집합이 어떤 집합인지 알려주는 연산
- 합집합(Union): 두 개의 원소가 포함된 집합을 하나의 집합으로 합치는 연산으로 동작 과정은 아래와 같다.
- 합집합(Union) 연산을 확인하여, 서로 연결된 두 노드 A, B를 확인한다
- A와 B의 루트 노드 A', B'를 각각 찾는다
- A'를 B'의 부모 노드로 설정한다.
- 모든 합집합(Union) 연산을 처리할 때까지 1번의 과정을 반복한다.
- 합집합(Union) 연산을 확인하여, 서로 연결된 두 노드 A, B를 확인한다
상세한 동작과정은 아래 이미지 참고 부탁드립니다.
서로소 집합 알고리즘 소스 코드
import java.util.*;
public class Main
{
public static int[] parents;
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
int nodeCnt = scan.nextInt();
int edgeCnt = scan.nextInt();
parents = new int[nodeCnt + 1];
for(int i = 0; i < parents.length; i++){
parents[i] = i;
}
for(int i = 0; i < edgeCnt; i++){
int x = scan.nextInt();
int y = scan.nextInt();
unionParent(x, y);
}
System.out.print("각 원소가 속한 집합: ");
for(int i = 1; i < parents.length; i++){
System.out.print(findParent(i) + " ");
}
System.out.print("\n부모 테이블: ");
for(int i = 1; i < parents.length; i++){
System.out.print(parents[i] + " ");
}
}
public static void unionParent(int x, int y){
int rootX = findParent(x);
int rootY = findParent(y);
if(rootX < rootY){
parents[rootY] = rootX;
}else{
parents[rootX] = rootY;
}
}
public static int findParent(int node){
return (node == parents[node] ? node : findParent(parents[node]));
}
}
| 입력 예시 | |
| 6 4 1 4 2 3 2 4 5 6 |
|
| 출력 예시 | |
| 각 원소가 속한 집합: 1 1 1 1 5 5 부모 테이블: 1 1 2 1 5 5 |
개선된 서로소 집합 알고리즘
기본적인 서로소 집합 알고리즘 코드에서는 루트 노드에 즉시 접근 할 수가 없다. 위 그림처럼 노드 3의 루트를 찾기 위해서는 노드 2로 이동한 다음 노드 3의 부모를 또 확인해서 노드 1로 접근해야 한다. 다시 말해 서로로 집합 알고리즘으로 루트를 찾기 위해서는 재귀적으로 부모를 거슬러 올라가야 한다. 이렇게 구현하면 답을 구할 수는 있지만 find 함수가 비효율적으로 동작한다. 최악의 경우 find 함수가 모든 노드를 다 확인하는 터라 시간 복잡도가 O(V)라는 점이다. 결과적으로 기존 알고리즘을 그대로 이용하게 되면 노드의 개수가 V개이고 find 혹은 union 연산의 개수가 M개일 때 총 시간 복잡도는 O(VM)이 되어 비효율적이다. 이러한 find 함수를 경로 압축이라는 간단한 방법으로 최적화할 수 있다.
- 경로 압축(Path Compression): 찾기(Find) 함수를 재귀적으로 호출한 뒤에 부모 테이블 값을 바로 갱신하는 기법
public static int findParent(int node){
if(node != parents[node]) {
parents[node] = findParent(parents[node]);
}
return parents[node];
}경로 압출 기법을 적용하면 각 노드에 대하여 찾기(Find) 함수를 호출한 이후에 해당 노드의 루트 노드가 바로 부모 노드가 되어 기본적인 방법에 비하여 시간 복잡도가 개선된다.
개선된 서로소 집합 알고리즘 소스 코드
import java.util.*;
public class Main
{
public static int[] parents;
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
int nodeCnt = scan.nextInt();
int edgeCnt = scan.nextInt();
parents = new int[nodeCnt + 1];
for(int i = 0; i < parents.length; i++){
parents[i] = i;
}
for(int i = 0; i < edgeCnt; i++){
int x = scan.nextInt();
int y = scan.nextInt();
unionParent(x, y);
}
System.out.print("각 원소가 속한 집합: ");
for(int i = 1; i < parents.length; i++){
System.out.print(findParent(i) + " ");
}
System.out.print("\n부모 테이블: ");
for(int i = 1; i < parents.length; i++){
System.out.print(parents[i] + " ");
}
}
public static void unionParent(int x, int y){
int rootX = findParent(x);
int rootY = findParent(y);
if(rootX < rootY){
parents[rootY] = rootX;
}else{
parents[rootX] = rootY;
}
}
public static int findParent(int node){
if(node != parents[node]) {
parents[node] = findParent(parents[node]);
}
return parents[node];
}
}
| 입력 예시 | |
| 6 4 1 4 2 3 2 4 5 6 |
|
| 출력 예시 | |
| 각 원소가 속한 집합: 1 1 1 1 5 5 부모 테이블: 1 1 1 1 5 5 |
서로소 집합을 활용한 사이클 판별
서로소 집합은 다양한 알고리즘에 사용될 수 있는데 특히 무방향 그래프 내에서 사이클을 판별할 때 사용할 수 있다는 특징이 있다. 서로소 집합의 합치기(Union) 연산은 그래프에서 간선으로 표현될 수 있다. 따라서 간선을 하나씩 확인하면서 두 노드가 포함되어 있는 집합을 합치는 과정을 반복하는 것만으로도 사이클을 판별할 수 있다. 알고리즘은 다음과 같다.
- 각 간선을 하나씩 확인하며 두 노드의 루트 노드를 확인한다.
- 루트 노드가 서로 다르다면 두 노드에 대하여 합집합(Union) 연산을 수행한다.
- 루트 노드가 서로 같다면 사이클(Cycle)이 발생한 것이다.
- 그래프에 포함되어 있는 모든 간선에 대하여 1번 과정을 반복한다.
상세한 동작과정은 아래 이미지 참고 부탁드립니다.
서로소 집합을 활용한 사이클 판별 소스 코드
import java.util.*;
public class Main
{
public static int[] parents;
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
int nodeCnt = scan.nextInt();
int edgeCnt = scan.nextInt();
boolean hasCycle = false;
parents = new int[nodeCnt + 1];
for(int i = 0; i < parents.length; i++){
parents[i] = i;
}
for(int i = 0; i < edgeCnt; i++){
int x = scan.nextInt();
int y = scan.nextInt();
if(findParent(x) == findParent(y)){
hasCycle = true;
break;
}
unionParent(x, y);
}
if (hasCycle) {
System.out.println("사이클이 발생했습니다.");
} else {
System.out.println("사이클이 발생하지 않았습니다.");
}
}
public static void unionParent(int x, int y){
int rootX = findParent(x);
int rootY = findParent(y);
if(rootX < rootY){
parents[y] = rootX;
}else{
parents[x] = rootY;
}
}
public static int findParent(int node){
// 루트 노드를 찾을 때까지 재귀 호출
if(node != parents[node]) {
parents[node] = findParent(parents[node]);
}
return parents[node];
}
}
| 입력 예시 | |
| 3 3 1 2 1 3 2 3 |
|
| 출력 예시 | |
| 사이클이 발생했습니다. |
신장 트리
그래프 알고리즘 문제로 자주 출제되는 문제 유형으로 하나의 그래프가 있을 때 모든 노드를 포함하면서 사이클이 존재하지 않는 부분 그래프를 의미한다. 이때 모든 노드가 포함되어 서로 연결되면서 사이클이 존재하지 않는다는 조건은 트리의 조건이기도 하다. 그래서 이러한 그래프를 신장 트리라고 부르는 것이다. 우리는 다양한 문제 상황에서 가능한 한 최소한의 비용으로 신장 트리를 찾아야 할 때가 있는데 이런 문제 상황에 사용되는 알고리즘을 최소 신장 트리 알고리즘이라고 한다.
크루스칼 알고리즘 (Kruskal Algorithm)
대표적인 최소 신장 트리 알고리즘으로 그리디 알고리즘으로 분류된다. 먼저 모든 간선에 대하여 정렬을 수행한 뒤에 가장 거리가 짧은 간선부터 집합에 포함시키면 된다. 이때 사이클을 발생시킬 수 잇는 간선의 경우 집합에 포함시키지 않는다. 구체적인 알고리즘 순서는 다음과 같다.
- 간선 데이터를 비용에 따라 오름차순으로 정렬한다.
- 간선을 하나씩 확인하며 현재의 간선이 사이클을 발생시키는지 확인한다.
- 사이클이 발생하지 않는 경우 최소 신장 트리에 포함시킨다.
- 사이클이 발생하는 경우 최소 신장 트리에 포함시킨다.
- 모든 간선에 대하여 2번의 과정을 반복한다.
크루스칼 알고리즘의 시간 복잡도는 간선의 개수가 E개일 때 O(ElogE)의 시간 복잡도를 가진다. 해당 알고리즘에서 시간이 가장 오래 걸리는 부분이 간선을 정렬하는 작업이기 때문에 간선의 정렬 시간으로 복잡도를 가진다.
상세한 동작과정은 아래 이미지 참고 부탁드립니다.
크루스칼 알고리즘 소스 코드
import java.util.*;
class Edge {
private int nodeX;
private int nodeY;
private int cost;
public Edge(int nodeX, int nodeY, int cost) {
this.nodeX = nodeX;
this.nodeY = nodeY;
this.cost = cost;
}
public int getNodeX() { return this.nodeX; }
public int getNodeY() { return this.nodeY; }
public int getCost() { return this.cost; }
}
public class Main
{
public static int[] parents;
public static ArrayList<Edge> edges = new ArrayList<>();
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
int nodeCnt = scan.nextInt();
int edgeCnt = scan.nextInt();
parents = new int[nodeCnt + 1];
for(int i = 0; i < parents.length; i++){
parents[i] = i;
}
for(int i = 0; i < edgeCnt; i++){
int x = scan.nextInt();
int y = scan.nextInt();
int cost = scan.nextInt();
edges.add(new Edge(x, y, cost));
}
edges.sort(Comparator.comparing(Edge::getCost));
int resultSum = 0;
for(Edge edge : edges){
int x = edge.getNodeX();
int y = edge.getNodeY();
//사이클이 생기는 경우 스킵
if (findParent(x) != findParent(y)) {
unionParent(x, y);
resultSum += edge.getCost();
}
}
System.out.println("result = " + resultSum);
}
public static void unionParent(int x, int y){
int rootX = findParent(x);
int rootY = findParent(y);
if(rootX < rootY){
parents[rootY] = rootX;
}else{
parents[rootX] = rootY;
}
}
public static int findParent(int node){
// 루트 노드를 찾을 때까지 재귀 호출
if(node != parents[node]) {
parents[node] = findParent(parents[node]);
}
return parents[node];
}
}
| 입력 예시 | 출력 예시 |
| 7 9 1 2 29 1 5 75 2 3 35 2 6 34 3 4 7 4 6 23 4 7 13 5 6 53 6 7 25 |
159 |
위상 정렬 (Topology Sort)
정렬 알고리즘의 일종으로 순서가 정해져 있는 일련의 작업을 차례대로 수행해야 할 때 사용할 수 있는 알고리즘이다. 즉 사이클이 없는 방향 그래프의 모든 노드를 방향성에 거스르지 않도록 순서대로 나열하는 것이다. 현실 세계의 전형적인 예시는 아래 그림과 같다. 위상 정렬은 순환하지 않는 방향 그래프(DAG, Direct Acyclic Graph)에 대해서만 수행할 수 있으며 모든 원소를 방문하기 전에 큐가 빈다면 사이클이 존재한다고 판단할 수 있다. 또한 위상 정렬을 수행할 때는 노드와 간선을 모두 확인해야 하기 때문에 O(V + E)의 시간 복잡도를 가진다.
- 진입차수(Indegree): 특정한 노드로 들어오는 간선의 개수
- 진출차수(Outdegree): 특정한 노드에서 나가는 간선의 개수
알고리즘은 다음과 같다.
- 진입차수가 0인 모든 노드를 큐에 넣는다.
- 큐가 빌 때까지 다음의 과정을 반복한다.
- 큐에서 원소를 꺼내 해당 노드에서 나가는 간선을 그래프에서 제거한다.
- 새롭게 진입차수가 0이 된 노드를 큐에 넣는다.
상세한 동작과정은 아래 이미지 참고 부탁드립니다.
위상 정렬 소스 코드
import java.util.*;
public class Main
{
public static int nodeCnt;
public static int edgeCnt;
public static int[] indegree;
public static ArrayList<ArrayList<Integer>> graph = new ArrayList<>();
public static Queue<Integer> queue = new LinkedList<>();
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
nodeCnt = scan.nextInt();
edgeCnt = scan.nextInt();
indegree = new int[nodeCnt + 1];
for(int i = 0; i <= nodeCnt; i++){
graph.add(new ArrayList<Integer>());
}
for(int i = 0; i < edgeCnt; i++){
int x = scan.nextInt();
int y = scan.nextInt();
indegree[y]++;
graph.get(x).add(y);
}
topologySort();
}
public static void topologySort() {
for (int i = 1; i < indegree.length; i++) {
if (indegree[i] == 0) {
queue.offer(i);
}
}
while(!queue.isEmpty()){
int now = queue.poll();
System.out.print(now + " ");
for(Integer child : graph.get(now)){
indegree[child]--;
if(indegree[child] == 0){
queue.offer(child);
}
}
}
}
}
| 입력 예시 | 출력 예시 |
| 7 8 1 2 1 5 2 3 2 6 3 4 4 7 5 6 6 4 |
1 2 5 3 6 4 7 |
예제 1 - 팀 결성
난이도 ●●○ | 풀이 시간 20분 | 시간 제한 2초 | 메모리 제한 128MB | 핵심 유형
학교에서 학생들에게 0번부터 N번까지의 번호를 부여했다. 처음에는 모든 학생이 서로 다른 팀으로 구분되어, 총 N + 1 개의 팀이 존재한다. 이때 선생님은 '팀 합치기'연산과 '같은 팀 여부 확인'연산을 사용할 수 있다.
- '팀 합치기' 연산은 두 팀을 합치는 연산이다.
- '같은 팀 여부 확인' 연산은 특정한 두 학생이 같은 팀에 속하는지를 확인하는 연산이다.
선생님이 M개의 연산을 수행할 수 있을 때, '같은 팀 여부 확인'연산에 대한 연산 결과를 출력하는 프로그램을 작성하시오.
입력 조건
- 첫째 줄에 N, M이 주어진다. M은 입력으로 주어지는 연산의 개수이다. (1 <= N, M <= 100,000)
다음 M개의 줄에는 각각의 연산이 주어진다. - '팀 합치기' 연산은 0 a b 형태로 주어진다. 이는 a번 학생이 속한 팀과 b번 학생이 속한 팀을 합친다는 의미이다.
- '같은 팀 여부 확인' 연산은 1 a b 형태로 주어진다. 이는 a번 학생과 b번 학생이 같은 팀에 속해 있는지를 확인하는 연산이다.
- a와 b는 N 이하의 양의 정수이다.
출력 조건
- '같은 팀 여부 확인'연산에 대하여 한 줄에 하나씩 YES 혹은 NO로 결과를 출력한다.
입력/출력 예시
| 입력 예시 | 출력 예시 |
| 7 8 0 1 3 1 1 7 0 7 6 1 7 1 0 3 7 0 4 2 0 1 1 1 1 1 |
NO NO YES |
요점
- 전형적인 서로소 집합 알고리즘 문제이다.
- N과 M의 범위가 모두 최대 100,000이기 때문에 경로 압축을 이용한 개선된 알고리즘을 사용해야 한다.
소스 코드
import java.util.*;
public class Main
{
public static int[] parents;
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
int nodeCnt = scan.nextInt();
int edgeCnt = scan.nextInt();
StringBuffer result = new StringBuffer();
parents = new int[nodeCnt + 1];
for(int i = 1; i < parents.length; i++){
parents[i] = i;
}
for(int i = 0; i < edgeCnt; i++){
int action = scan.nextInt();
int x = scan.nextInt();
int y = scan.nextInt();
if(action == 0){
unionTeam(x, y);
}else if(action == 1){
result.append(findTeam(x) == findTeam(y) ? "YES" : "NO");
result.append("\n");
}
}
System.out.println(result.toString());
}
public static void unionTeam(int x, int y) {
int rootX = findTeam(x);
int rootY = findTeam(y);
if(rootX < rootY){ parents[rootX] = rootY; }
else { parents[rootY] = rootY; }
}
public static int findTeam(int team) {
if(team != parents[team]){
parents[team] = findTeam(parents[team]);
}
return parents[team];
}
}
예제 2 - 도시 분할 계획
난이도 ●●○ | 풀이 시간 40분 | 시간 제한 2초 | 메모리 제한 256MB | 기초 문제집
동물원에서 막 탈출한 원숭이 한 마리가 세상 구경을 하고 있다. 어느 날 원숭이는 '평화로운 마을'에 잠시 머물렀는데 마침 마을 사람들은 도로 공사 문제로 머리를 맞대고 회의 중이었다.
마을은 N개의 집과 그 집들을 연결하는 M개의 길로 이루어져 있다. 길은 어느 방향으로든지 다닐 수 있는 편리한 길이다. 그리고 길마다 길을 유지하는데 드는 유지비가 있다.
마을의 이장은 마을을 2개의 분리된 마을로 분할할 계획을 세우고 있다. 마을이 너무 커서 혼자서는 관리할 수 없기 때문이다. 마을을 분할할 때는 각 분리된 마을 안에 집들이 서로 연결되도록 분할해야 한다. 각 분리된 마을 안에 있는 임의의 두 집 사이에 경로가 항상 존재해야 한다는 뜻이다. 마을에는 집이 하나 이상 있어야 한다.
그렇게 마을의 이장은 계획을 세우다가 마을 안에 길이 너무 많다는 생각을 하게 되었다. 일단 분리된 두 마을 사이에 있는 길들은 필요가 없으므로 없앨 수 있다. 그리고 각 분리된 마을 안에서도 임의의 두 집 사이에 경로가 항상 존재하게 하면서 길을 더 없앨 수 있다. 마을의 이장은 위 조건을 만족하도록 길들을 모두 없애고 나머지 길의 유지비의 합을 최소로 하고 싶다. 이것을 구하는 프로그램을 작성하시오.
입력 조건
- 첫째 줄에 집의 개수 N, 길의 개수 M이 주어진다. N은 2 이상 100,000 이하인 정수이고, M은 1 이상 1,000,000 이하인 정수이다.
- 그 다음 줄부터 M줄에 걸쳐 길의 정보가 A, B, C 3개의 정수로 공백으로 구분되어 주어지는데 A번 집과 B번 집을 연결하는 길의 유지비가 C(1 <= C <= 1,000) 라는 뜻이다.
출력 조건
- 첫째 줄에 길을 없애고 남은 유지비 합의 최솟값을 출력한다.
입력/출력 예시
| 입력 예시 | 출력 예시 |
| 7 12 1 2 3 1 3 2 3 2 1 2 5 2 3 4 4 7 3 6 5 1 5 1 6 2 6 4 1 6 5 3 4 5 3 6 7 4 |
8 |
요점
- 전체 그래프에서 2개의 최소 신장 트리를 만들어야 한다.
- 크루스칼 알고리즘으로 최소 신장 트리를 찾은 뒤에 가장 비용이 큰 간선을 제거한다.
소스 코드
import java.util.*;
class Edge{
int cityA;
int cityB;
int cost;
public Edge(int cityA, int cityB, int cost){
this.cityA = cityA;
this.cityB = cityB;
this.cost = cost;
}
public int getCityA(){ return this.cityA; }
public int getCityB(){ return this.cityB; }
public int getCost(){ return this.cost; }
}
public class Main
{
public static int[] parents;
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
int nodeCnt = scan.nextInt();
int edgeCnt = scan.nextInt();
parents = new int[nodeCnt + 1];
ArrayList<Edge> edges = new ArrayList<>();
for(int i = 1; i <= nodeCnt; i++){
parents[i] = i;
}
for(int i = 1; i <= edgeCnt; i++){
int cityA = scan.nextInt();
int cityB = scan.nextInt();
int cost = scan.nextInt();
edges.add(new Edge(cityA, cityB, cost));
}
edges.sort(Comparator.comparing(Edge::getCost));
int resultSum = 0;
int maxCost = -1;
for(Edge edge : edges){
int cityA = edge.getCityA();
int cityB = edge.getCityB();
int cost = edge.getCost();
if(findParent(cityA) == findParent(cityB)) continue;
unionParent(cityA, cityB);
resultSum += cost;
maxCost = Math.max(maxCost, cost);
}
System.out.println("result = " + (resultSum - maxCost));
}
public static void unionParent(int a, int b){
int rootA = findParent(a);
int rootB = findParent(b);
if(rootA < rootB){
parents[rootA] = rootB;
} else {
parents[rootB] = rootA;
}
}
public static int findParent(int city){
if(city != parents[city]) {
parents[city] = findParent(parents[city]);
}
return parents[city];
}
}
예제 3 - 커리큘럼
난이도 ●●● | 풀이 시간 50분 | 시간 제한 2초 | 메모리 제한 128MB | 핵심 유형
동빈이는 온라인으로 컴퓨터 공학 강의를 듣고 있다. 이때 각 온라인 강의는 선수 강의가 있을 수 있는데, 선수 강의가 있는 강의는 선수 강의를 먼저 들어야만 해당 강의를 들을 수 있다. 동빈이는 총 N개의 강의를 듣고자 한다. 강의는 1번부터 N번까지의 번호를 가진다. 또한 동시에 여러 개의 강의를 들을 수 있다고 가정한다. 예를 들어, N = 3일 때, 3번 강의의 선수 강의로 1번과 2번 강의가 있고, 1번과 2번 강의는 선수 강의가 없다고 하자. 그리고 각 강의에 대하여 강의 시간이 다음과 같다고 하자.
1번 강의: 30시간
2번 강의: 20시간
3번 강의: 40시간
이 경우, 1번 강의를 수강하기까지의 최소 시간은 30시간, 2번 강의를 수강하기까지는 최소 20시간, 3번 강의를 수강하기까지는 최소 70시간이 필요하다. 동빈이가 듣고자 하는 N개의 강의 정보가 주어졌을 때, N개의 강의에 대하여 수강하기까지는 걸리는 최소 시간을 출력하는 프로그램을 작성해라.
입력 조건
- 첫째줄에 동빈이가 듣고자 하는 강의의 수 N(1 <= N <= 500)이 주어진다.
- 다음 N개의 줄에는 각 강의의 강의시간과 그 강의를 듣기 위해 먼저 들어야 하는 강의들의 번호가 자연수로 주어지며, 각 자연수는 공백으로 구분된다. 이 때 강의 시간은 100,000 이하의 자연수이다.
- 각 강의 번호는 1부터 N까지로 구성되며, 각 줄은 -1로 끝난다.
출력 조건
- N개의 강의에 대해 수강하기까지 걸리는 최소 시간을 한 줄에 하나씩 출력한다.
입력/출력 예시
| 입력 예시 | 출력 예시 |
| 5 10 -1 10 1 -1 4 1 -1 4 3 1 -1 3 3 -1 |
10 20 14 18 17 |
요점
- 위상 정렬 알고리즘의 응용 문제이다.
- 인접한 노드에 대하여 현재보다 강의 시간이 더 긴 경우를 찾는다면, 더 오랜 시간이 걸리는 경우의 시간 값을 저장하는 방식으로 결과 테이블을 갱신한다.
소스 코드
import java.util.*;
public class Main
{
public static int nodeCnt;
public static int[] time;
public static int[] input;
public static ArrayList<ArrayList<Integer>> required= new ArrayList<>();
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
nodeCnt = scan.nextInt();
time = new int[nodeCnt + 1];
input = new int[nodeCnt + 1];
for(int i = 0; i <= nodeCnt; i++){
required.add(new ArrayList<Integer>());
if(i != 0){
time[i] = scan.nextInt();
while(true){
int x = scan.nextInt();
if(x == -1){ break; }
input[i]++;
required.get(x).add(i);
}
}
}
topologySort();
}
public static void topologySort(){
int[] result = Arrays.copyOf(time, nodeCnt+1);
Queue<Integer> queue = new LinkedList<>();
for(int i = 1 ; i <= nodeCnt; i++){
if(input[i] == 0){
queue.offer(i);
}
}
while(!queue.isEmpty()){
int now = queue.poll();
for(Integer subject : required.get(now)){
result[subject] = Math.max(result[subject], result[now] + time[subject]);
input[subject]--;
if(input[subject] == 0){
queue.offer(subject);
}
}
}
Arrays.stream(result).skip(1).forEach(System.out::println);
}
}
그래프 이론 예제를 풀어본 후
정말 세상에는 똑똑한 사람이 정말 많은 것 같다. 다들 이런 알고리즘을 어떻게 생각해냈는지 만들고 되게 기분이 좋으셨을 것 같다. 이번에도 최단 경로처럼 이해하는데 큰 어려움은 없었는데 서로수 집합 알고리즘의 경우 대체 어느 상황에 쓰는 알고리즘인지 잘 모르겠다. 사이클을 찾는 용도로만 쓰기에는 좀 아쉬운 것 같은데 예제로 나온 문제도 단순히 서로수 집합 알고리즘을 그래도 말로 풀어놓은 것 같은 예제라 아쉬운 마음이 든다. 다음에 서로수 집합 예제를 한번 더 찾아봐야겠다.
GitHub: https://github.com/Leeyeonjae/coding-test/tree/main/10_Graph
참고서적 : 이것이 취업을 위한 코딩 테스트다 with 파이썬 by 나동빈