
들어가기 앞서
개발 환경
- OS: macOS Big Sur 11.5.2
- IDE: Visual Studio Code, RubyMine를 혼용하여 사용
(책에서는 AWS Cloud9 IDE 환경에서 사용) - Ruby: ruby 2.6.9p207 (2021-11-24 revision 67954) [x86_64-darwin20]
- Ruby on Rails: Rails 5.1.6
- SCM: GitHub
AWS Cloud9 환경이 아닌 로컬환경에서 실행하였기 때문에 루비와 레일즈 설치는 가이드 문서를 보고 진행하였다.
클라우드 IDE를 사용할 경우 책의 내용을 따라 하면 된다.
지난 글
3장 이후부터는 계속 Sample 애플리케이션을 보완해 나가는 방식으로 튜토리얼이 진행될 예정이다. 따라서 이전 글을 먼저 읽고 오길 권장한다.
[Ruby on Rails Tutorial] 5장 레이아웃의 작성: SASS, Asset Pipeline, Named Path, 통합테스트
들어가기 앞서 개발 환경 OS: macOS Big Sur 11.5.2 IDE: Visual Studio Code, RubyMine를 혼용하여 사용 (책에서는 AWS Cloud9 IDE 환경에서 사용) Ruby: ruby 2.6.9p207 (2021-11-24 revision 67954) [x86_64-darwin20] Ruby on Rails: Rails 5.
jellili.tistory.com
목표
6장부터 12장에 걸쳐 레일즈의 로그인과 인증 시스템을 개발해볼 것이다. 그 첫 번째 시작인 이번 장에서는 유저의 데이터 모델을 작성하고, 데이터를 저장하기 위한 수단을 확보하는 방법에 대해 학습할 예정이다.
User 모델
8장까지의 최종 목표는 사용자 등록용 페이지를 작성하는 것이다. 그러나 지금 상태에서는 신규 사용자의 정보가 등록되어도 해당 정보를 저장할 저장소가 없다. 페이지를 작성하기 전 사용자 정보를 저장할 수 있는 데이터 구조를 만들 필요가 있다.
브랜치 생성
이번 장에서는 별도로 프로젝트를 생성하지 않고 3장에서 만든 Sample App에 계속해서 작업을 이어갈 것이다. Git에서 버전을 관리하고 있다면 master 브랜치에서 작업하는 것이 아닌 작업 당시의 토픽 브랜치를 작성하여 작업하는 것이 좋다. 다음 명령어를 이용하여 루비 학습 용 브랜치를 생성하겠다.
$ git checkout -b modeling-users
모델(Model)
레일즈에서는 데이터 모델로 사용하기 위한 데이터 구조를 모델(Model)이라 하고 이는 앞서 1장에서 설명했던 MVC의 M을 담당한다. 데이터를 장기적으로 저장하기 위한 기본 방법으로는 데이터베이스(DB, Database)를 사용하고 있다. 이때, DB와의 통신을 담당하는 레일즈의 기본 라이브러리는 Active Record로 데이터 객체의 생성/저장/검색을 위한 메서드를 가지고 있다. 해당 라이브러리의 메서드 사용 시 SQL을 의식할 필요가 없다는 장점이 있다. 게다가 레일즈에는 마이그레이션(Migration) 기능이 있어 데이터 정의를 루비로 작성할 수 있어 SQL의 DDL을 새롭게 배울 필요가 없다. 즉, 레일즈는 데이터베이스의 세부적인 사항을 거의 완전하게 숨기고 있다. 실제로 본 튜토리얼에서는 SQLite를 개발환경에서 사용할 것이며 책에서는 PostgreSQL를 실제 배포환경에서 사용하지만 데이터 저장방법에 대해서는 고민할 필요가 거의 없다.
Database
4장에서 만들었던 커스텀 클래스 User를 떠올려보자. 이 클래스는 name과 email을 속성으로 가지는 사용자 객체로 해당 섹션을 이해하기 위해 사용되었지만 영속성(Persistence)에 대한 내용이 빠져있었다. 레일즈 콘솔에서 클래스의 객체를 생성하여도 콘솔에서 exit하면 해당 객체는 바로 삭제되었다. 이번에는 삭제되지 않는 유저 모델을 구축해 볼 것이다. 기존과 마찬가지로 name과 email 속성을 가진 유저를 모델링하는 것부터 시작해보자. 여기서는 email를 유니크한 값으로 사용해보겠다.


우리는 이전에 new 액션을 가진 유저 컨트롤러를 생성하기 위해 다음과 같은 명령어를 사용했었다.
$ rails generate controller Users new모델을 생성할 때는 위 명령어와 비슷한 패턴으로 generate model 명령어를 사용한다. 추가로 이번에는 name과 email 속성을 더한 User 모델을 생성할 것이기 때문에 실제로 사용할 명령어는 아래와 같다. 이때 컨트롤러는 Users, 모델은 User로 명령어를 작성하는데 이것은 컨트롤러 이름에는 복수형을 사용하고 모델에는 단수형을 사용하는 관습이니 알아두도록 하자.
name:string나 email:string을 매개변수로 넘김으로써 데이터베이스에서 사용하고자 하는 2개의 속성을 레일즈에 입력한다. 이때 이러한 속성의 타입정보도 같이 전달되는 이 경우에는 string이다.
generate 명령어의 결과를 보면 알 수 있듯 마이그레이션이라고 불리는 새로운 파일이 생성됐다. 마이그레이션은 데이터베이스의 구조를 변경하는 수단을 제공하여 데이터베이스의 구조가 변경되었을 때 손쉽게 데이터 모델을 변경할 수 있다. 이 경우 마이그레이션은 모델 생성 스크립트에 의해 자동적으로 작성된다. 이때 마이그레이션 파일 이름에는 해당 파일이 생성된 시간의 타임스탬프가 접두사로 들어가는데 이는 동시 개발 시 충돌을 방지한다.
$ rails generate model User name:string email:string
invoke active_record
create db/migrate/20230612152112_create_users.rb
create app/models/user.rb
invoke test_unit
create test/models/user_test.rb
create test/fixtures/users.yml마이그레이션 파일 자체는 데이터베이스에 변경사항을 정의하는 change 메서드의 모임이다. 여기서 change 메서드는 create_table라고 하는 레일즈의 메서드를 호출해서 테이블을 데이터베이스에 생성한다. 또 create_table 메서드는 1개의 블록 변수를 가지는 블록을 사용하는데 여기서는 table의 앞문자를 따서 t를 블록 변수로 사용한다. 해당 블록 안에서 t 오브젝트를 사용하여 name과 email 컬럼을 데이터베이스에 작성한다. 자료형은 둘 다 string이다.
모델이름은 단수형(User)이지만 테이블 이름은 복수형(users)이다. 이것은 레일즈에서의 관습을 그대로 적용하고 있다. 모델은 하나의 유저를 나타내는 것에 반해 데이터베이스의 테이블은 여러 유저들로 구성된다.
블록의 마지막 행 t.timestamp는 특별한 명령어로 created_at과 update_at이라는 2개의 매직 컬럼(Magic Columns)을 생성한다. 어떤 유저가 생성 혹은 갱신되었을 때 해당 시각을 자동적으로 기록하는 타임스탬프이다.
# db/migrate/[timestamp]_create_users.rb
class CreateUsers < ActiveRecord::Migration[5.0]
def change
create_table :users do |t|
t.string :name
t.string :email
t.timestamps
end
end
end마이그레이션에 의해 생성된 완전한 데이터 모델은 아래와 같다.
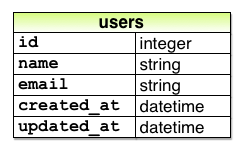
마이그레이션은 db:migrate 명령어를 사용하여 실행할 수 있으며 이것을 마이그레이션의 적용(migrating up)이라고 한다. 처음 db:migrate를 실행하면 db/development.sqlite3라고 하는 파일이 생성된다. 이것은 SQLite 데이터베이스의 실체로 RubyMine을 사용하는 경우 플러그인을 설치하여 확인할 수도 있고 DB Browser for SQLite와 같은 별도의 프로그램을 사용하여 확인할 수도 있다. 하는 멋진 프로그램을 사용하면 데이터베이스의 구조를 확인할 수 있다.
$ rails db:migrate클라우드 IDE를 사용하는 경우에는 아래 첫 번째 그림처럼 일단 파일을 로컬환경으로 다운로드할 필요가 있다.

결과는 다음과 같다. 앞서 마이그레이션에 의해 생성된 데이터 모델과 비교해 보자. 이때 id라고 하는 컬럼은 2장에서 간단하게 설명한 것처럼 자동으로 생성되며 레일즈가 각 데이터를 유니크하게 인식하기 위해 사용한다.

💡롤백(Rollback)
거의 모든 마이그레이션은 원래의 상태로 되돌리는 것이 가능하고 적어도 본 튜토리얼에서 모든 마이그레이션 파일은 원래대로 되돌릴 수 있다. 여기서 원래대로 되돌리는 것을 롤백(Rollback)이라고 하며 db:rollback 명령어로 실행할 수 있다.
아래 명령어를 실행하기 전 db/schema.rb의 내용을 확인해 보자. 해당 파일은 데이터베이스의 구조인 스키마(Schema)를 확인하기 위해 사용된다.
$ rails db:rollback롤백 커맨드 실행 후 db/schema.rb의 내용을 확인하여 롤백이 성공했는지 확인해 보자. 성공했다면 다시 한번 마이그레이션을 실행하여 원래대로 되돌리도록 하자.
$ rails db:migrate
Model 파일
앞에서 generate model을 실행한 것으로 user.rb 파일이 생성되었다. 해당 파일을 자세히 살펴보도록 하자. User 클래스는 ApplicationRecord를 상속하고 있어 자동으로 ActiveRecord::Base 클래스의 모든 기능을 가지게 된다.
# app/models/user.rb
class User < ApplicationRecord
end
User 객체 생성
4장과 마찬가지로 레일즈 콘솔을 사용하여 데이터 모델에 대해 알아보도록 하겠다. 해당 과정에서 데이터베이스에 영향을 주지 않기 위해 콘솔의 샌드박스 모드를 사용할 예정이다. "Any modifications you make will be rolled back on exit"라는 메시지에서 알 수 있듯이 샌드박스 모드로 콘솔을 실행하게 되면 콘솔 종료 시 데이터베이스 등에 적용된 변경 사항을 모두 적용취소(롤백)한다.
$ rails console --sandbox
Loading development environment in sandbox
Any modifications you make will be rolled back on exit
>>4장에서는 example_user 파일을 명시적으로 require 하기 전까지 사용자 객체에 접근이 불가했지만 모델을 사용하면 상황이 달라진다. 레일즈 콘솔은 기동 시 레일즈의 환경을 자동적으로 읽어 들이며 여기에는 모델도 포함된다. 즉, 새로운 사용자 객체를 생성할 때는 추가 작업을 하지 않아도 된다는 것이다. 다음 출력은 사용자 객체를 콘솔에서 출력한 것이다. User.new를 매개변수 없이 호출한 경우 모든 속성이 nil의 객체를 가진다.
>> User.new
=> #<User id: nil, name: nil, email: nil, created_at: nil, updated_at: nil>ActiveRecord는 해시(hash)를 매개변수로 사용한다. 그리고 User 모델은 ActiveRecord를 상속받고 있어 다음과 같이 초기화가 가능하다.
>> user = User.new(name: "Michael Hartl", email: "mhartl@example.com")
=> #<User id: nil, name: "Michael Hartl", email: "mhartl@example.com", created_at: nil, updated_at: nil>해당 객체를 이해하기 위해서는 유효성(Validity) 개념에 대한 이해도 필요하다. 자세하게 설명하기 전 user 객체가 유효한지 확인해 보자. 이때 유효성을 확인하기 위해서는 valid? 메서드를 사용하면 된다. 현시점에 user 객체는 메모리 상에서만 존재할 뿐이지 데이터베이스에 저장된 상태는 아니다. 그럼에도 true를 반환한 것을 통해 유효성은 객체 자체를 확인하는 것이지 데이터베이스 저장 여부와는 관계없다는 것을 알 수 있다.
>> user.valid?
true데이터베이스에 user 객체를 저장하기 위해선 user 객체에서 save 메서드를 호출할 필요가 있다. save 메서드는 성공하면 true 실패하면 false를 리턴하며 콘솔에서는 SQL Query나 결과가 표시된다.
>> user.save
(0.1ms) SAVEPOINT active_record_1
SQL (1.4ms) INSERT INTO "users" ("name", "email", "created_at", "updated_at") VALUES (?, ?, ?, ?) [["name", "Lee"], ["email", "test"], ["created_at", "2023-06-16 05:57:32.185780"], ["updated_at", "2023-06-16 05:57:32.185780"]]
(0.1ms) RELEASE SAVEPOINT active_record_1
=> true유저 객체를 생성했을 때는 id 속성과 매직컬럼인 created_at, updated_at 속성의 값이 모두 nil이 되어 있었을 것이다. save 메서드를 실행한 후에는 어떻게 변경되었는지 확인해 보자. id에는 1이 들어가 있다. 매직컬럼에는 현재 시간이 입력되어 있는 것을 확인할 수 있을 것이다. 생성과 갱신의 타임스탬프는 현재 똑같은 값이지만 데이터를 갱신하면 두 개의 값이 달라질 것이다.
>> user
=> #<User id: 1, name: "Michael Hartl", email: "mhartl@example.com", created_at: "2023-06-16 05:57:32", updated_at: "2023-06-16 05:57:32">4장과 마찬가지로 User 모델의 객체도 닷기법을 사용하여 해당 속성에 접근할 수 있다.
>> user.name
=> "Michael Hartl"
>> user.email
=> "mhartl@example.com"
>> user.updated_at
=> Fri, 16 Jun 2023 05:57:32 UTC +00:00여기까지는 객체를 생성하고 save 메서드를 사용하여 저장하는 과정을 따로 진행했다. 그러나 ActiveRecord에서는 User.create로 모델의 생성과 저장을 동시에 하는 방법도 제공한다. User.create는 논리값(true/false)을 반환하는 대신 객체 자신을 리턴한다. 리턴된 객체는 변수에 대입할 수도 있다.
>> User.create(name: "A Nother", email: "another@example.org")
(0.1ms) SAVEPOINT active_record_1
SQL (0.1ms) INSERT INTO "users" ("name", "email", "created_at", "updated_at") VALUES (?, ?, ?, ?) [["name", "A Nother"], ["email", "another@example.org"], ["created_at", "2023-06-16 07:01:15.218072"], ["updated_at", "2023-06-16 07:01:15.218072"]]
(0.1ms) RELEASE SAVEPOINT active_record_1
=> #<User id: 2, name: "A Nother", email: "another@example.org", created_at: "2023-06-16 07:01:15", updated_at: "2023-06-16 07:01:15">
>> foo = User.create(name: "Foo", email: "foo@bar.com")
(0.1ms) SAVEPOINT active_record_1
SQL (0.1ms) INSERT INTO "users" ("name", "email", "created_at", "updated_at") VALUES (?, ?, ?, ?) [["name", "Foo"], ["email", "foo@bar.com"], ["created_at", "2023-06-16 07:01:31.173512"], ["updated_at", "2023-06-16 07:01:31.173512"]]
(0.1ms) RELEASE SAVEPOINT active_record_1
=> #<User id: 3, name: "Foo", email: "foo@bar.com", created_at: "2023-06-16 07:01:31", updated_at: "2023-06-16 07:01:31">destroy는 create의 반대이다. create와 마찬가지로 destroy는 해당 객체 자신을 리턴 하지만 다시 destroy를 실행할 수는 없다.
>> foo.destroy
(0.1ms) SAVEPOINT active_record_1
SQL (0.1ms) DELETE FROM "users" WHERE "users"."id" = ? [["id", 3]]
(0.1ms) RELEASE SAVEPOINT active_record_1
=> #<User id: 3, name: "Foo", email: "foo@bar.com", created_at: "2023-06-16 07:01:31", updated_at: "2023-06-16 07:01:31">게다가 삭제된 객체는 다음과 같이 메모리에 남아있다.
>> foo
=> #<User id: 3, name: "Foo", email: "foo@bar.com", created_at: "2023-06-16 07:01:31", updated_at: "2023-06-16 07:01:31">
User 객체 검색
ActiveRecord는 객체를 검색하기 위한 몇 가지 방법을 제공하고 있다. 이 기능들을 사용하여 앞에서 작성한 첫 번째 사용자를 검색해 보고 세 번째 사용자(foo)가 삭제되는 것을 확인해 보자. 다음 코드에서는 User.find의 사용자 id를 넘기고 그 결과로 ActiveRecord는 해당 id의 사용자를 리턴하고 있다.
>> User.find(1)
User Load (0.1ms) SELECT "users".* FROM "users" WHERE "users"."id" = ? LIMIT ? [["id", 1], ["LIMIT", 1]]
=> #<User id: 1, name: "Michael Hartl", email: "mhartl@example.com", created_at: "2023-06-16 05:57:32", updated_at: "2023-06-16 05:57:32">이번에는 id=3인 사용자가 데이터베이스에 존재하는지 확인해 보겠다. 앞에서 destroy 메서드를 사용하여 3번째 사용자를 삭제했기 때문에 ActiveRecord는 해당 사용자를 데이터베이스 안에서 찾을 수 없고 이에 find 메서드의 예외(Exception)를 확인할 수 있다. 예외란 프로그램이 실행될 때 어떠한 예외적인 이벤트가 발생한 것을 나타내며 이 경우 Active Record::RecordNotFound라는 예외가 발생하고 있다.
>> User.find(3)
User Load (0.1ms) SELECT "users".* FROM "users" WHERE "users"."id" = ? LIMIT ? [["id", 3], ["LIMIT", 1]]
Traceback (most recent call last):
1: from (irb):13
ActiveRecord::RecordNotFound (Couldn't find User with 'id'=3)id가 아닌 특정한 속성으로 사용자를 검색할 수 있는 방법도 있다.
>> User.find_by(email: "mhartl@example.com")
=> #<User id: 1, name: "Michael Hartl", email: "mhartl@example.com", created_at: "2023-06-16 05:57:32", updated_at: "2023-06-16 05:57:32">사용자를 검색하는 다른 방법들을 소개해보자면 일단은 first 메서드이다. first 메서드는 단어의 의미 그대로 데이터베이스의 제일 첫 번째 데이터를 조회한다.
>> User.first
=> #<User id: 1, name: "Michael Hartl", email: "mhartl@example.com", created_at: "2023-06-16 05:57:32", updated_at: "2023-06-16 05:57:32">다음으로 all 메서드는 데이터베이스 내 모든 사용자 객체를 조회한다. 이때 습득한 객체의 유형이 ActiveRecord::Relation인데 이것은 해당 객체 배열을 효율적으로 다루기 위한 클래스이다.
>> User.all
=> #<ActiveRecord::Relation [#<User id: 1, name: "Michael Hartl",email: "mhartl@example.com", created_at: "2023-06-16 05:57:32", updated_at: "2023-06-16 05:57:32">, #<User id: 2, name: "A Nother", email: "another@example.org", created_at: "2023-06-16 07:01:15", updated_at: "2023-06-16 07:01:15">]>
User 객체 수정
이번에는 앞에서 만든 객체를 수정해 보도록 하겠다. 기본적인 수정 방법은 2가지이다. 첫 번째 방법은 속성을 개별적으로 대입하는 것이다.
>> user
=> #<User id: 1, name: "Michael Hartl", email: "mhartl@example.com", created_at: "2023-06-16 05:57:32", updated_at: "2023-06-16 05:57:32">
>> user.email = "mhartl@example.net"
=> "mhartl@example.net"
>> user.save
(0.1ms) SAVEPOINT active_record_1
SQL (0.1ms) UPDATE "users" SET "email" = ?, "updated_at" = ? WHERE "users"."id" = ? [["email", "mhartl@example.net"], ["updated_at", "2023-06-16 07:30:26.725749"], ["id", 1]]
(0.0ms) RELEASE SAVEPOINT active_record_1
=> trueuser.save를 실행하여 사용자 정보를 수정해 보았다. 이때 매직컬럼의 수정 날짜가 변하는 것을 확인할 수 있다.
>> user.created_at
=> Fri, 16 Jun 2023 05:57:32 UTC +00:00
>> user.updated_at
=> Fri, 16 Jun 2023 07:30:26 UTC +00:00변경 사항을 데이터베이스에 저장하기 위해선 마지막에 save를 실행할 필요가 있다는 것을 잊어선 안된다. 저장을 하지 않고 reload를 실행해 버리면 데이터베이스의 정보는 수정 전의 객체를 다시 읽어 들이기 때문에 다음과 같은 결과가 나온다.
>> user.email
=> "mhartl@example.net"
>> user.email = "foo@bar.com"
=> "foo@bar.com"
>> user.reload.email
=> "mhartl@example.net"속성을 수정하는 다른 한 가지 방법은 update_attributes를 사용하는 것이다. 해당 메서드는 속성의 해시 값을 받아 수정에 성공한다면 수정과 동시에 데이터베이스로 저장을 진행하고 성공 시 true를 리턴한다. 단 실패 시 메서드의 실행이 실패된다.
>> user.update_attributes(name: "The Dude", email: "dude@abides.org")
=> true
>> user.name
=> "The Dude"
>> user.email
=> "dude@abides.org"특정 속성만 수정하고 싶을 때에는 다음과 같이 update_attributes를 사용한다. update_attributes는 데이터의 검증을 회피하는 효과도 있다.
>> user.update_attribute(:name, "El Duderino")
=> true
>> user.name
=> "El Duderino"
User 검증
속성 name과 email에 모든 문자열을 저장할 수 있는 것은 바람직하지 않다. 예를 들어 name은 빈 문자열이면 안 되며 email은 메일 주소의 포맷에 따라 입력되는 것이 바람직할 것이다. 따라서 해당 속성 값에 제약을 걸어둘 필요가 있다. ActiveRecord에서는 검증(Validation) 기능을 통해 속성 값에 제약을 걸 수 있다. 이번 섹션에서는 자주 사용되는 케이스들 중 유효성(Validity)의 검증, 존재성(presence)의 검증, 길이(length)의 검증, 포맷(format)의 검증, 유니크성(uniqueness)의 검증을 알아볼 것이고 다음 섹션에서 최종 적인 검증방법으로 확인(Confirmation)을 추가해 볼 것이다.
유효성 검증
3장에서 언급한 것처럼 테스트 주도 개발이 항상 정답이라고 할 수는 없지만 모델의 검증 기능은 테스트 주도 개발론과 궁합이 아주 잘 맞는다. 일단 유효한 모델 객체를 작성하고 해당 속성 중 하나를 유효하지 않은 속성으로 의도적으로 변경해 보자. 그리고 검증 단계에서 실패하는지 어떤지를 테스트해 보는 식으로 진행하겠다. 문제의 주체가 검증 기능인지 객체인지 구분하기 위해 유효한 상태에 대해서도 테스트 케이스 결과를 확인해 보자.
generate 명령어의 결과로 이미 User를 위한 테스트 코드 기반이 작성되어 있을 것이다.
# test/models/user_test.rb
require 'test_helper'
class UserTest < ActiveSupport::TestCase
# test "the truth" do
# assert true
# end
end먼저 객체의 유효성 검증을 위한 테스트 코드 작성을 위해 setup이라는 특수한 메서드를 사용하여 유효한 User객체(@user)를 생성한다. 이때 setup 메서드는 각 테스트 코드가 실행되기 직전에 실행된다.
@user는 인스턴스 변수로 setup 메서드 내부에 선언함으로써 모든 테스트 케이스 내부에서 해당 인스턴스 변수를 사용할 수 있게 된다. 테스트 케이스에서는 valid? 메서드를 사용하여 사용자 객체의 유효성을 테스트해 볼 수 있다.
다음 코드는 심플한 assert 메서드를 사용하여 테스트를 진행한다. @user.valid? 가 true를 리턴하면 성공 false를 리턴하면 실패하는 것이다.
# test/models/user_test.rb
require 'test_helper'
class UserTest < ActiveSupport::TestCase
def setup
@user = User.new(name: "Example User", email: "user@example.com")
end
test "should be valid" do
assert @user.valid?
end
end모델에 관한 테스트만 실행하기 위해 다음 명령어를 실행해 보자.
$ rails test:models
존재성 검증
아마도 제일 기본적인 검증은 존재성(Presence)일 것이다. 단순히 매개변수로 넘겨진 속성이 존재하는지를 검증한다. 여기서는 name 속성의 존재성 테스트를 추가해 보겠다.
아래의 코드와 같이 @user 객체의 name 속성에 공백의 문자열을 지정한다. 그 후 assert_not 메서드를 사용하여 @user 객체가 유효하지 않다는 것을 확인해 보겠다. 이 시점에서 모델 테스트는 실패(RED)일 것이다.
# test/models/user_test.rb
require 'test_helper'
class UserTest < ActiveSupport::TestCase
def setup
@user = User.new(name: "Example User", email: "user@example.com")
end
test "should be valid" do
assert @user.valid?
end
# name 속성을 검증해보는 테스트
test "name should be present" do
@user.name = " "
assert_not @user.valid?
end
endname 속성의 존재를 검증하는 방법은 아래의 코드처럼 validates 메서드에 옵션 해시 presence: true를 매개변수를 설정하여 사용할 수 있다.
# app/models/user.rb
class User < ApplicationRecord
validates :name, presence: true
end괄호를 사용하여 위 코드를 아래와 같이 바꿀 수도 있다.
class User < ApplicationRecord
validates(:name, presence: true)
end콘솔을 이용하여 User 모델의 검증 기능이 작동되는 것을 확인해 보자. 이렇게 user 객체가 유효한지 valid? 메서드로 체크할 수 있다. valid? 메서드는 객체가 1개 이상의 검증을 실패했을 때 false를 리턴하고 모든 검증에 통과했을 때 true를 리턴한다.
$ rails console --sandbox
>> user = User.new(name: "", email: "mhartl@example.com")
>> user.valid?
=> false지금 같은 경우에는 검증 케이스가 1개밖에 없기 때문에 어떠한 이유로 실패했는지를 쉽게 파악할 수 있다. 그러나 대부분의 경우에는 실패했을 때 발생하는 error 객체를 사용하는 방법이 더욱 편리하다.
>> user.errors.full_messages
=> ["Name can't be blank"]객체가 유효하지 않기 때문에 데이터베이스 저장은 자동으로 실패하게 된다.
>> user.save
=> false위 변경에 의해 assert_not을 사용한 테스트는 통과하게 될 것이다. 앞서 설명한 방법대로 email 속성에 대한 존재성 테스트와 validates 메서드를 설정해 보자.
# test/models/user_test.rb
require 'test_helper'
class UserTest < ActiveSupport::TestCase
def setup
@user = User.new(name: "Example User", email: "user@example.com")
end
test "should be valid" do
assert @user.valid?
end
test "name should be present" do
@user.name = ""
assert_not @user.valid?
end
# Add email test case
test "email should be present" do
@user.email = " "
assert_not @user.valid?
end
end# app/models/user.rb
class User < ApplicationRecord
validates :name, presence: true
validates :email, presence: true
end이것으로 모든 존재성을 체크할 수 있게 되었고 테스트 결과 또한 성공(GREEN)이 될 것이다.
길이 검증
각 사용자는 반드시 이름을 가지고 있도록 존재성 검증을 추가하였다. 그러나 이것만으로는 충분하지 않다. 사용자 이름은 사이트에 표시되기 때문에 길이에도 제한을 걸 필요가 있다. 단순하게 50글자로 제한을 둘 것이다.
또한 너무 긴 메일 주소에 대해서도 검증을 추가해 보겠다. 대부분의 데이터베이스는 문자열 제한을 255 문자로 하고 있기 때문에 거기에 맞추어 255 문자로 맞출 예정이다.
# test/models/user_test.rb
require 'test_helper'
class UserTest < ActiveSupport::TestCase
def setup
@user = User.new(name: "Example User", email: "user@example.com")
end
.
.
.
test "name should not be too long" do
@user.name = "a" * 51
assert_not @user.valid?
end
test "email should not be too long" do
@user.email = "a" * 244 + "@example.com"
assert_not @user.valid?
end
end테스트 코드에서는 51 문자의 문자열을 간단하게 작성하기 위해 문자열에 곱셈하는 방법을 사용했다. 결과는 아래와 같다.
>> "a" * 51
=> "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa"
>> ("a" * 51).length
=> 51메일 주소 길이에 대한 검증에서도 다음과 같이 긴 문자열을 작성해서 검증을 수행하였다.
>> "a" * 244 + "@example.com"
=> "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
a@example.com"
>> ("a" * 244 + "@example.com").length
=> 256지금 시점에서 작성한 테스트 케이스는 실패한다. 테스트를 통과시키기 위해서는 길이를 강제하기 위한 매개변수를 지정할 필요가 있다. :maximum와 같이 사용할 수 있는 :length는 길이를 제한할 수 있다.
# app/models/user.rb
class User < ApplicationRecord
validates :name, presence: true, length: { maximum: 50 }
validates :email, presence: true, length: { maximum: 255 }
end매개변수 추가 후 테스트 통과를 확인할 수 있다.
포맷 검증
지금까지는 빈 공백의 메일주소만 금지했지만 이번에는 메일주소가 정해진 포맷(user@example.com)을 충족하고 있는지도 확인해 보겠다. 제일 처음으로 유효한 메일주소와 무효한 메일주소 컬렉션에 대한 테스트를 진행해 보자.
컬렉션을 만들기 위해 다음과 같이 문자열 배열을 간단하게 만들 수 있는 %w[]을 알아놓을 필요가 있다. each 메서드를 사용하여 addresses 배열의 각 요소를 반복하여 출력할 수 있다. 이 기술을 알고 있다면 메일주소 포맷 검증 테스트 코드를 작성할 준비가 된 것이다.
>> %w[foo bar baz]
=> ["foo", "bar", "baz"]
>> addresses = %w[USER@foo.COM THE_US-ER@foo.bar.org first.last@foo.jp]
=> ["USER@foo.COM", "THE_US-ER@foo.bar.org", "first.last@foo.jp"]
>> addresses.each do |address|
?> puts address
>> end
USER@foo.COM
THE_US-ER@foo.bar.org
first.last@foo.jp메일주소는 검증 테스트를 수행하기 어려우며 에러가 발생하기 쉬운 부분이다. 유효한 메일주소와 무효한 메일 주소를 준비를 하고 검증범위 내에서의 에러를 찾아내도록 하겠다. 구체적으로는 user@examplecom과 같은 유효하지 않은 메일 주소가 테스트에서 통과하지 않는 것과 user@example.com과 같은 유효한 메일 주소가 테스트에서 통과하는 것을 확인해 가며 검증 작업을 진행해 가겠다.
일단 유효한 메일주소 테스트는 아래와 같다. 여기서는 assert 메서드의 두 번째 매개변수로 에러 메시지를 추가하고 있다. 이 매개변수로 인해 어떤 메일주소가 테스트에서 실패하는지를 확인해 볼 수 있다
# test/models/user_test.rb
require 'test_helper'
class UserTest < ActiveSupport::TestCase
def setup
@user = User.new(name: "Example User", email: "user@example.com")
end
.
.
.
test "email validation should accept valid addresses" do
valid_addresses = %w[user@example.com USER@foo.COM A_US-ER@foo.bar.org
first.last@foo.jp alice+bob@baz.cn]
valid_addresses.each do |valid_address|
@user.email = valid_address
assert @user.valid?, "#{valid_address.inspect} should be valid"
end
end
end그다음으로 user@example,com(점이 아닌 컴마로 되어 있다.)이나 user_at_foo.org(앳마크 @가 없다.) 등과 같은 유효하지 않은 메일주소를 사용하여 무효성(Invalidity)에 대해 테스트해 보자.
# test/models/user_test.rb
require 'test_helper'
class UserTest < ActiveSupport::TestCase
def setup
@user = User.new(name: "Example User", email: "user@example.com")
end
.
.
.
test "email validation should reject invalid addresses" do
invalid_addresses = %w[user@example,com user_at_foo.org user.name@example.
foo@bar_baz.com foo@bar+baz.com]
invalid_addresses.each do |invalid_address|
@user.email = invalid_address
assert_not @user.valid?, "#{invalid_address.inspect} should be invalid"
end
end
end지금 이 시점에서는 테스트가 실패할 것이다.
$ rails test메일주소의 포맷을 검증하기 위해선 다음과 같이 format 옵션을 사용해야 한다. 아래 옵션은 매개변수에 정규표현(Regular Expression 또는 regex)을 입력한다. 정규표현은 언뜻 봐선 굉장히 복잡하고 어려워 보이지만 문자열의 패턴매칭에 있어서는 매우 강력한 언어이다.
validates :email, format: { with: /<regular expression>/ }우리는 유효한 메일주소만 찾아내고 무효한 메일주소는 무시하는 정규표현을 작성할 필요가 있다. 메일주소의 표준을 정하는 공식사이트에는 완전한 정규표현이 있지만 매우 크고 알 수 없는 정규표현이어서 경우에 따라서는 역효과를 낼 수 있다. 본 튜토리얼에서는 조금 더 실용적이고 간결하며 실전에서 보증된 정규표현을 사용해 보겠다.
VALID_EMAIL_REGEX = /\A[\w+\-.]+@[a-z\d\-.]+\.[a-z]+\z/i정규표현을 이해하기 위해서 좀 더 세분화한 표를 보고 이해할 필요가 있다.
| 정규표현 | 의미 |
| / | 정규식의 시작 |
| \A | 문자열의 시작 |
| [\w+-.]+ | 영문자, 숫자, 언더바(_), 플러스(+), 마이너스(-), 점(.) 중 적어도 한가지를 1문자 이상 반복한다. |
| @ | 앳(@) |
| [a-z\d-.]+ | 소문자, 숫자, 마이너스, 점 중 최소한 적어도 한 1문자 이상 반복한다. |
| . | 점(dot) |
| [a-z]+ | 영소문자를 적어도 한 글자 이상 반복한다. |
| \z | 문자열의 끝 |
| / | 정규식의 끝 |
| i | 대소문자 무시 옵션 |
정규표현을 제대로 이해하기 위해선 실제로 사용해 보는 것이 제일 빠릅니다. Rubular에서는 정규표현을 시험해 볼 수 있는 기능을 제공한다. 해당 웹사이트에서 정규식을 테스트해 보는 것을 추천한다. (주의: 위 정규표현을 Rubular에서 사용할 경우 정규표현의 앞뒤의 \A와 \z를 제거하고 테스트하도록 하자. 이렇게 함으로써 여러 개의 메일주소를 한 번에 검사할 수 있다. 또한 Rubular에 슬래시 /../의 내부 부분을 작성하는 것만으로도 동작하기 때문에 양 끝에 있는 슬래시 또한 제외하도록 한다.)

정규표현을 적용하여 email의 포맷을 검증한 결과는 아래와 같다. 여기서 VALID_EMAIL_REGEX는 상수인데 루비에서 대문자로 시작하는 이름은 상수를 의미한다.
# app/models/user.rb
class User < ApplicationRecord
validates :name, presence: true, length: { maximum: 50 }
VALID_EMAIL_REGEX = /\A[\w+\-.]+@[a-z\d\-.]+\.[a-z]+\z/i
validates :email, presence: true, length: { maximum: 255 },
format: { with: VALID_EMAIL_REGEX }
end그러나 위 정규표현은 주의해야 할 점이 있다. foo@bar..com과 같은 점이 연속으로 있는 메일주소는 검출해 낼 수 없다. 혹시 해당 경우 또한 검출하고 싶다면 아래와 같이 정규식을 수정할 수 있다.
# app/models/user.rb
class User < ApplicationRecord
validates :name, presence: true, length: { maximum: 50 }
VALID_EMAIL_REGEX = /\A[\w+\-.]+@[a-z\d\-]+(\.[a-z\d\-]+)*\.[a-z]+\z/i
validates :email, presence: true, length: { maximum: 255 },
format: { with: VALID_EMAIL_REGEX }
end다시 한번 테스트를 수행하면 포맷 검증 테스트가 통과하는 것을 확인할 수 있다.
유니크성 검증
메일 주소를 유니크하게 유지하기 위해 validates 메서드의 :unique 옵션을 사용해 보자. 단 여기서 중요한 사항이 있다. 지금까지 우리는 모델 테스트를 위해 User.new를 사용해 왔다. 그러나 이 메서드는 단순히 메모리 상에서 루비 객체를 생성할 뿐이지 데이터베이스에는 등록되지 않는다. 즉 유니크성을 테스트하기 위해서는 메모리가 아닌 데이터베이스에 등록해야 할 필요가 있다.
일단 메일 주소 테스트 코드를 작성해 보자. 다음 코드에서 사용하는 dup 메서드 같은 속성을 가진 데이터를 복제할 때 사용한다. @user를 저장한 다음에는 복제한 사용자의 메일주소가 이미 데이터베이스에 존재하기 때문에 유효하지 않아야 한다.
# test/models/user_test.rb
require 'test_helper'
class UserTest < ActiveSupport::TestCase
def setup
@user = User.new(name: "Example User", email: "user@example.com")
end
.
.
.
test "email addresses should be unique" do
duplicate_user = @user.dup
@user.save
assert_not duplicate_user.valid?
end
end위 테스트 케이스를 통과시키기 위해서 uniqueness: true 옵션을 추가한다.
# app/models/user.rb
class User < ApplicationRecord
validates :name, presence: true, length: { maximum: 50 }
VALID_EMAIL_REGEX = /\A[\w+\-.]+@[a-z\d\-.]+\.[a-z]+\z/i
validates :email, presence: true, length: { maximum: 255 },
format: { with: VALID_EMAIL_REGEX },
uniqueness: true
end한 가지 덧붙이자면 보통 메일주소는 대문자 소문자가 구별되지 않는다. 즉 foo@bar.com, FOO@BAR.COM, Foo@BAr.com이라고 써도 다루는 것은 똑같다. 그러므로 메일주소의 검증에서는 이러한 경우도 고려해야 할 필요가 있다. 이 때문에 대문자를 구별하지 않고 테스트하는 것이 중요하며 실제 테스트 코드에서는 아래와 같이 해야 한다.
# test/models/user_test.rb
require 'test_helper'
class UserTest < ActiveSupport::TestCase
def setup
@user = User.new(name: "Example User", email: "user@example.com")
end
.
.
.
test "email addresses should be unique" do
duplicate_user = @user.dup
duplicate_user.email = @user.email.upcase #추가된 코드
@user.save
assert_not duplicate_user.valid?
end
end만약 위 테스트가 조금 추상적인 것 같다고 느끼신다면 레일즈 콘솔을 이용하여 확인해 보는 것을 추천한다. 현재의 유니크성 검증에서는 대문자 소문자를 구별하고 있기 때문에 duplicate_user.valid?는 true가 된다. 그러나 여기서 false가 될 필요가 있다.
$ rails console --sandbox
>> user = User.create(name: "Example User", email: "user@example.com")
>> user.email.upcase
=> "USER@EXAMPLE.COM"
>> duplicate_user = user.dup
>> duplicate_user.email = user.email.upcase
>> duplicate_user.valid?
=> true다행히 :uniqueness에서는 :case_sensitive라고 하는 옵션을 사용할 수 있다. 이전에 uniqueness: true에서 true를 case_sensitvie: false로 바꾸었을 뿐이다. 레일즈는 이 경우 알아서 :uniqueness를 true로 판단한다.
# app/models/user.rb
class User < ApplicationRecord
validates :name, presence: true, length: { maximum: 50 }
VALID_EMAIL_REGEX = /\A[\w+\-.]+@[a-z\d\-.]+\.[a-z]+\z/i
validates :email, presence: true, length: { maximum: 255 },
format: { with: VALID_EMAIL_REGEX },
uniqueness: { case_sensitive: false } #추가된 코드
end이 시점에서 애플리케이션은 메일 주소의 유니크성을 강제하고 있기 때문에 테스트 코드는 통과할 것이다.
$ rails test그러나 한 가지 의문점이 남아있다. ActiveRecord는 데이터베이스 레벨에서 유니크성을 보장하고 있지 않다는 점이다.
구체적인 시나리오를 사용하여 해당 문제를 설명해 보겠다.
- 앨리스가 샘플 애플리케이션에 사용자를 등록한다. 이때 메일 주소는 alice@wonderland.com이다.
- 앨리스는 실수로 Submit을 재빠르게 두 번 클릭해 버렸고 서버로 요청이 2번 연속 송신되어
- 다음과 같은 순으로 문제가 발생한다.
- 요청 1은 여러 가지 메일 주소에 대한 검증을 통과하는 사용자를 메모리 상에 생성한다.
- 요청 2도 마찬가지로 동작해 요청 1의 유저는 저장되고 요청 2의 유저도 저장된다.
- 이 결과 유니크성의 검증이 이루어졌음에도 불구하고 같은 메일주소를 가진 2개의 사용자 레코드가 생성된다.
위와 같은 시나리오는 믿기 어려울 수도 있겠지만 레일즈 웹 사이트에서는 트래픽이 많은 경우 이러한 문제가 발생할 가능성이 있다. 다행히도 해결책의 구현은 간단한다. 사실 이 문제는 데이터베이스 레벨에서도 유니크성을 강제한다면 해결되는 문제이다. 구체적으로는 데이터베이스상의 email 컬럼에 인덱스(Index)를 추가하여 해당 인덱스가 단 하나만 존재하게 한다면 문제는 해결된다.
email 인덱스를 추가한다면 데이터모델링 변경이 필요한다. 레일즈에서는 마이그레이션으로 인덱스를 추가한다. User모델을 생성할 때는 자동으로 새로운 마이그레이션이 생성되었지만 이번에는 기존에 존재했던 모델에 구조를 추가하기 때문에 다음과 같이 마이그레이션을 직접 생성할 필요가 있다.
$ rails generate migration add_index_to_users_emailUser 모델의 마이그레이션과는 다르게 메일주소의 유니크성은 정의되어있지 않아 아래 코드와 같이 정의할 필요가 있다. 해당 코드에서는 users 모델의 email 컬럼에 인덱스를 추가하기 위해 add_index라는 레일즈 메서드를 사용하고 있다. 인덱스 자체는 유니크성을 가지고 있지 않지만 옵션으로 unique: true를 지정하여 강제할 수 있도록 하였다.
# db/migrate/[timestamp]_add_index_to_users_email.rb
class AddIndexToUsersEmail < ActiveRecord::Migration[5.0]
def change
add_index :users, :email, unique: true
end
end마지막으로 데이터베이스를 마이그레이션 하겠다. (명령어 실행이 실패하는 경우 실행 중인 샌드박스 콘솔의 세션을 종료하고 재시도해보자. 해당 세션이 데이터베이스를 Lock 하고 있어 마이그레이션이 되지 않을 가능성이 있다.)
$ rails db:migrate지금 다시 테스트를 수행해 보면 모두 실패(RED)로 변경된 것을 확인할 수 있다. 이는 데이터베이스용 샘플 데이터가 포함되어 있는 fixture 내부에서 유니크성이 보장되어 있지 않기 때문이다. 즉 User 모델 생성 시 fixture가 자동으로 생성됐지만 메일주소가 중복되는 무효한 데이터로 이루어져 있어 오류를 발생시킨다.
# test/fixtures/users.yml
# Read about fixtures at http://api.rubyonrails.org/classes/ActiveRecord/
# FixtureSet.html
one:
name: MyString
email: MyString
two:
name: MyString
email: MyStringfixture는 8장까지 사용하지 않을 예정이기 때문에 지금 당장은 해당 데이터를 삭제해 놓고 User용의 fixture파일을 빈 파일로 만들어놓겠다. 이후 테스트를 수행하면 성공(GREEN)으로 변경된 것을 확인할 수 있다.
# test/fixtures/users.yml
# 파일 내용을 전부 삭제해놓습니다.메일 주소의 유니크성을 보증하기 위해서는 또 다른 하나의 문제를 해결해야 한다. 바로 데이터베이스의 대소문자 구별 문제이다. 예를 들어 데이터베이스에 따라 Foo@ExAMPle.COm과 foo@example.com는 다른 문자열이라고 읽어 들이는 경우가 있지만 Sample 애플리케이션에서는 해당 문자열을 같은 문자열이라고 인식해야 한다. 이를 위해 "데이터베이스에 저장되기 직전에 모든 문자열을 소문자로 변환한다"라는 대책을 세워보겠다. 이것을 구현하기 위해 ActiveRecord의 콜백(callback) 메서드를 이용한다.
콜백 메서드는 특정 시점에서 호출되는 메서드로 이번 경우에는 객체가 저장되는 시점에 처리하고자 하기 때문에 before_save 콜백을 사용하도록 하겠다. 이걸로 사용자를 데이터베이스에 저장하기 전에 email 속성을 강제적으로 소문자로 변환한다. 생성한 코드는 아래와 같다. 코드에서는 before_save 콜백에 블록을 넘기고 블록에서 메일 주소의 현재의 값을 String 클래스의 downcase 메서드를 사용하여 소문자로 변경하고 있다. 이때 User 모델 안에서 오른쪽의 self는 생략이 가능하지만 왼쪽의 self는 생략이 불가능하다.
# app/models/user.rb
class User < ApplicationRecord
before_save { self.email = email.downcase } # 추가 된 코드
validates :name, presence: true, length: { maximum: 50 }
VALID_EMAIL_REGEX = /\A[\w+\-.]+@[a-z\d\-.]+\.[a-z]+\z/i
validates :email, presence: true, length: { maximum: 255 },
format: { with: VALID_EMAIL_REGEX },
uniqueness: { case_sensitive: false }
end이것으로 앞에서 정의한 앨리스의 시나리오는 제대로 핸들링할 수 있게 되었다. 데이터베이스는 제일 첫 요청을 확인하고 레코드를 저장하지만 2번째에서는 유니크 제약으로 인해 저장하지 않고 에러를 출력한다. 게다가 인덱스를 email 속성에 추가한 것으로 인해 "여러 데이터가 있을 때 검색효율을 향상하자"라는 목표도 달성하였다. email 속성에 인덱스를 부여함으로 메일주소로 유저를 검색할 때 풀데이터 스캔을 하지 않아도 된다.
안전한 비밀번호 추가
이름과 메일주소에 대한 검증을 추가했으니 마지막으로 안전한 비밀번호에 대한 작업을 진행해 보도록 하자. 시나리오는 사용자에게 비밀번호와 비밀번호 확인을 입력하도록 하여 해당 값을 해시화하여 데이터베이스에 저장하는 것이다. 여기서 해시화라는 것은 루비의 데이터 구조 중 하나인 해시를 의미하는 것이 아니라 해시 함수를 사용하여 입력된 데이터를 복호화할 수 없는 데이터로 만드는 처리를 의미한다.
8장에서 자세히 설명할 테지만 해시화된 비밀번호는 로그인 구조에서 인증(authenticate) 처리를 위해 사용될 예정이다. 인증 과정은 크게 비밀번호 송신, 해시화, 데이터베이스 내부의 해시화된 값과 비교하는 순서로 진행된다. 이렇게 하면 데이터베이스에 실제 비밀번호를 저장할 필요가 없어 해킹을 당하였다고 해도 비밀번호의 안정성이 높아진다.
비밀번호 해시화
안전한 비밀번호의 구현은 has_secure_password라고 하는 레일즈의 메서드를 호출하는 것만으로도 대부분 해결된다. 해당 메서드는 다음과 같이 호출이 가능한데 단순한 호출만으로도 아래와 같은 기능을 사용할 수 있게 된다.
- 안전하게 해시화된 비밀번호를 데이터베이스 내부의 password_digest 속성에 저장할 수 있게 된다.
- 쌍으로 이루어진 가상의 속성(password와 password_confirmation)을 사용할 수 있게 되고 존재성과 값이 일치하는지의 검증이 추가된다.
- authenticate 메서드를 사용할 수 있게 된다.
(매개변수의 문자열이 비밀번호와 일치하면 User 객체를 리턴하고 그렇지 않으면 false를 리턴하는 메서드)
마법과 같은 has_secure_password 기능을 사용하는 것에는 조건이 있다. 모델 내부에서 password_digest라고 하는 속성이 포함되어 있어야 한다. 이번에는 User 모델에서 사용하기 때문에 User의 데이터모델은 다음과 같이 변경된다.

그림과 같이 데이터모델을 변경하기 위해선 일단 password_digest 컬럼을 추가하는 적절한 마이그레이션을 생성한다. 마이그레이션 이름은 자유롭게 지정할 수 있지만 다음과 같이 말미에 to_users로 해놓는 것을 권장한다. 이렇게 하면 users 테이블에 컬럼을 추가하는 마이그레이션이 레일즈에 의해 자동적으로 생성되기 때문이다.
add_password_digest_to_users라는 마이그레이션 파일을 생성하기 위해 다음의 명령어를 실행한다. 명령어 실행 시 password_digest:string를 매개변수로 넘겨 필요한 속성 이름과 형태 정보를 넘기고 있다. 맨 처음 users 테이블을 생성할 때와 마찬가지로 마이그레이션을 생성하기 위한 충분한 정보를 레일즈에 입력하고 있음을 알 수 있다.
$ rails generate migration add_password_digest_to_users password_digest:string마이그레이션 코드에서는 add_column 메서드를 사용하여 users 테이블 password_digest 컬럼을 추가하고 있다.
# db/migrate/[timestamp]_add_password_digest_to_users.rb
class AddPasswordDigestToUsers < ActiveRecord::Migration[5.0]
def change
add_column :users, :password_digest, :string
end
end적용을 위해서는 데이터베이스 마이그레이션을 실행한다.
$ rails db:migratehas_secure_password를 사용하여 비밀번호를 해시화하기 위해 최첨단 해시함수인 bcrypt가 필요한다. 비밀번호를 적절하게 해시화함으로써 공격으로 인한 데이터베이스 해킹이 발생하였다 해도 사이트에는 로그인할 수 없을 것이다. Sample 애플리케이션에 bcrypt를 사용하기 위해 bcrypt gem을 Gemfile에 추가한다.
source 'https://rubygems.org'
gem 'rails', '5.1.6'
gem 'bcrypt', '3.1.12'
.
.
.다음으로 언제나처럼 bundle install을 실행한다.
$ bundle install
안전한 비밀번호 검증
User모델에 password_digest 속성을 추가하여 Gemfile에 bcrypt를 추가한 것으로 드디어 User모델 안에서 has_secure_password를 사용할 수 있게 되었다.
# app/models/user.rb
class User < ApplicationRecord
before_save { self.email = email.downcase }
validates :name, presence: true, length: { maximum: 50 }
VALID_EMAIL_REGEX = /\A[\w+\-.]+@[a-z\d\-.]+\.[a-z]+\z/i
validates :email, presence: true, length: { maximum: 255 },
format: { with: VALID_EMAIL_REGEX },
uniqueness: { case_sensitive: false }
has_secure_password #추가한 코드
end지금 테스트를 수행해 보면 실패(RED)하는 것을 확인할 수 있다. 테스트가 실패하는 이유는 has_secure_password에서 password와 password_confirmaition 속성에 대한 검증 테스트를 강제적으로 추가하고 있기 때문이다. 그러나 우리의 테스트 코드에는 아래와 같은 값밖에 설정하고 있지 않다.
def setup
@user = User.new(name: "Example User", email: "user@example.com")
end테스트를 통과하게 하기 위해서는 아래와 같은 비밀번호와 비밀번호 확인값을 추가해야 한다.
# test/models/user_test.rb
equire 'test_helper'
class UserTest < ActiveSupport::TestCase
def setup
@user = User.new(name: "Example User", email: "user@example.com",
password: "foobar", password_confirmation: "foobar") #추가한 코드
end
.
.
.
end변경한 코드에서는 테스트가 성공(GREEN)하는 것을 확인할 수 있다.
비밀번호 자릿수 제한
일반적으로 대부분의 사이트는 비밀번호를 간단하지 않게 설정하도록 최소문자수를 설정해 놓는다. 레일즈에서 비밀번호 길이를 설정하는 방법은 많이 있지만 이번에는 간결하게 공백 문자와 6자리 미만 문자열은 불가하도록 설정해 보겠다. 비밀번호 길이가 6자리 이상인 것을 검증하는 테스트는 아래의 코드와 같다.
# test/models/users_test.rb
require 'test_helper'
class UserTest < ActiveSupport::TestCase
def setup
@user = User.new(name: "Example User", email: "user@example.com",
password: "foobar", password_confirmation: "foobar")
end
.
.
.
test "password should be present (nonblank)" do
@user.password = @user.password_confirmation = " " * 6
assert_not @user.valid?
end
test "password should have a minimum length" do
@user.password = @user.password_confirmation = "a" * 5
assert_not @user.valid?
end
end위에서 다음과 같이 다중 대입(Multiple Assignment)을 사용하는 것을 볼 수 있다. 비밀번호와 비밀번호 확인에 대해 동시에 값을 대입하는 것이다.
@user.password = @user.password_confirmation = "a" * 5이전 코드에서는 maximum을 이용하여 사용자 이름의 최대문자수를 제한하고 있었다. 이것과 닮은 방식으로 minimum 옵션을 사용하여 최소문자수 검증을 구현할 수 있다. 또한 빈 공백의 비밀번호를 방지하기 위해 존재성의 검증도 같이 추가해 보자. 결과적으로 코드는 아래와 같이 된다. 여담으로 has_secure_password 메서드는 존재성 검증도 같이 해주지만 새로운 레코드가 추가되었을 때만 적용되는 특징이 있다. 따라서 예를 들어 사용자가 6 문자 이상의 공백스페이스 등의 문자열을 비밀번호란에 입력하여 갱신하려고 한다면 검증이 적용되지 않고 갱신되어 버리는 문제가 발생할 수 있다.
# app/models/users.rb
class User < ApplicationRecord
before_save { self.email = email.downcase }
validates :name, presence: true, length: { maximum: 50 }
VALID_EMAIL_REGEX = /\A[\w+\-.]+@[a-z\d\-.]+\.[a-z]+\z/i
validates :email, presence: true, length: { maximum: 255 },
format: { with: VALID_EMAIL_REGEX },
uniqueness: { case_sensitive: false }
has_secure_password
validates :password, presence: true, length: { minimum: 6 } # 추가된 코드
end이 시점에서 테스트는 통과할 것이다.
사용자 생성과 인증
이상으로 User 모델의 기본적인 틀은 완성되었다. 이번에는 7장에서 사용자 정보 표시 페이지를 작성할 것을 대비하여 데이터베이스에 신규 사용자를 1명 생성해 보자. 추가로 has_secure_password를 설정한 효과에 대해서도 함께 확인해 보겠다. 웹 화면 처리는 아직 되어있지 않기 때문에 이번에는 레일즈 콘솔을 사용하여 사용자를 수동으로 생성해 보도록 하겠다. 앞서 설명한 create를 사용할 예정이며 실제로 데이터베이스에 반영이 되어야 하기 때문에 샌드박스 환경은 사용하지 않겠습니다
$ rails console
>> User.create(name: "Michael Hartl", email: "mhartl@example.com",
?> password: "foobar", password_confirmation: "foobar")
=> #<User id: 1, name: "Michael Hartl", email: "mhartl@example.com", created_at: "2023-06-19 07:29:22", updated_at: "2023-06-19 07:29:22", password_digest: "$2a$10$RtqLgoPDCwWE1.3iGKtqNuwvhFGUeeejssh8x5S83Za...">제대로 데이터베이스에 저장되었는지 확인하기 위해 개발용 데이터베이스를 DB Browser for SQLite로 열고 users테이블을 확인해 보자.(혹시 클라우드 IDE를 사용하고 있는 경우라면 데이터베이스의 파일을 다운로드하여 확인하자.) 이때 사전에 정의한 User 모델 속성에 대응한 컬럼이 존재하고 있는 것도 함께 확인해 보자.

콘솔로 되돌아가 password_digest 속성을 확인해 보면 has_secure_password의 효과를 확인해 볼 수 있다. User 객체를 생성할 때 "foobar" 문자열이 해시화된 결과이다. bcrypt를 사용하여 생성했기 때문에 해당 문자열로부터 원래의 비밀번호를 도출해 내는 것은 비현실적이다.
>> user = User.find_by(email: "mhartl@example.com")
>> user.password_digest
=> "$2a$10$xxucoRlMp06RLJSfWpZ8hO8Dt9AZXlGRi3usP3njQg3yOcVFzb6oK"또한has_secure_password를 User모델에 추가함으로써 해당 객체 내부에서 authenticate 메서드를 사용할 수 있게 되었다. 이 메서드는 매개변수로 넘겨진 문자열(비밀번호)을 해시화한 값과 데이터베이스에 있는 password_digest 컬럼의 값을 비교한다. 테스트를 위해 아까 작성한 user 객체에 대해 잘못된 비밀번호를 집어넣어 보면 false를 리턴하는 것을 알 수 있다.
>> user.authenticate("not_the_right_password")
false
>> user.authenticate("foobaz")
false다음으로 제대로 된 비밀번호를 입력해 보면 이번에는 authenticate가 해당 유저의 객체를 리턴하는 것을 알 수 있다. 8장에서는 이 authenticate 메서드를 사용하여 로그인하는 방법에 대해 설명해 보겠다.
>> user.authenticate("foobar")
=> #<User id: 1, name: "Michael Hartl", email: "mhartl@example.com",created_at: "2016-05-23 20:36:46", updated_at: "2016-05-23 20:36:46",password_digest: "$2a$10$xxucoRlMp06RLJSfWpZ8hO8Dt9AZXlGRi3usP3njQg3...">
또한 authenticate 가 User객체를 리턴하는 것은 중요하지 않으며 리턴 받은 값의 논리값이 true가 되는 것이 중요한다. !!를 이용한다면 user.authenticate를 또 다르게 활용할 수도 있을 것이다.
>> !!user.authenticate("foobar")
=> true
브랜치 머지
다음 장으로 넘어가기 변경 내역을 커밋(Commit)하고 마스터 브랜치(Master branch)에 머지(Merge)하도록 하겠다. 습관적으로 원격 레포지토리에 푸시(Push)를 하거나 배포하기 전에 테스트 코드를 실행하여 기존 동작에 영향이 없는지 확인해 보도록 하자.
$ rails test
$ git add -A
$ git commit -m "Make a basic User model (including secure passwords)"
$ git checkout master
$ git merge modeling-users
$ git push
글을 마치며
6장에서는 아래와 같은 내용을 배울 수 있었다.
- 마이그레이션을 사용하여 애플리케이션의 데이터 모델을 수정할 수 있다.
- ActiveRecord를 사용하여 데이터 모델을 생성/조작하거나 하기 위한 많은 메서드를 사용할 수 있다.
- ActiveRecord의 검증(Validation)을 사용하면 모델에 대한 제한을 추가할 수 있다.
- 자주 사용하는 검증으로는 존재성 길이 포맷 등이 있다.
- 정규표현은 수수께끼처럼 보이지만 매우 강력한다.
- 데이터베이스에 인덱스를 추가하는 것으로 검색 효율을 향상할 수 있고 데이터베이스 레벨에서의 유니크성을 보증할 수 있다.
- has_secure_password 메서드를 사용하는 것으로 모델에 대한 안전한 비밀번호를 추가할 수 있다.
오늘 작성한 코드 또한 아래 GitHub에서 확인할 수 있으니 참고 바란다.
GitHub - Leeyeonjae/rails-sample-app
Contribute to Leeyeonjae/rails-sample-app development by creating an account on GitHub.
github.com
참고 자료 및 사이트
- https://www.railstutorial.org/
- https://github.com/Yoodahun/Rails_Tutorials_Translation
- https://ko.wikipedia.org/wiki/%ED%95%B4%EC%8B%9C_%ED%95%A8%EC%88%98